


Criando um cluster com Apache Hadoop do 0
- #Hadoop
 Imagem apache hadoop
Imagem apache hadoop
Hoje eu gostaria de mostrar para vocês como montar seu primeiro cluster Hadoop On-Premise Hands-On.
- Primeiramente estarei usando a distribuição CentOS7 do Linuxs para esse tutorial.
- Use a maquina virtual que você desejar.
- Lembre-se de quando você estiver configurando a sua maquina virtual, não esqueça de mudar o tipo de adaptador de rede de NAT para Bridged Adapter, para que está maquina consiga pegar o IP da sua rede.
- Na instalação do Linux em Localization vá em Date & Time e coloque na sua região e de OK.
- Mais para baixo em System, clique em installation destination veja se o HD da VM está marcada e clique em Done.

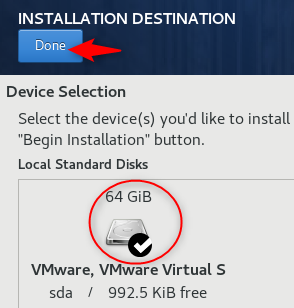
Após marcar o HD, clique em DONE.
- E por ultimo em Network & Host Name é muito importante que você configure corretamente agora para que não precise alterar mais tarde!.

- Habilite a interface de rede e em baixo em Host name vamos colocar o nome da maquina e clique em apply e Done.
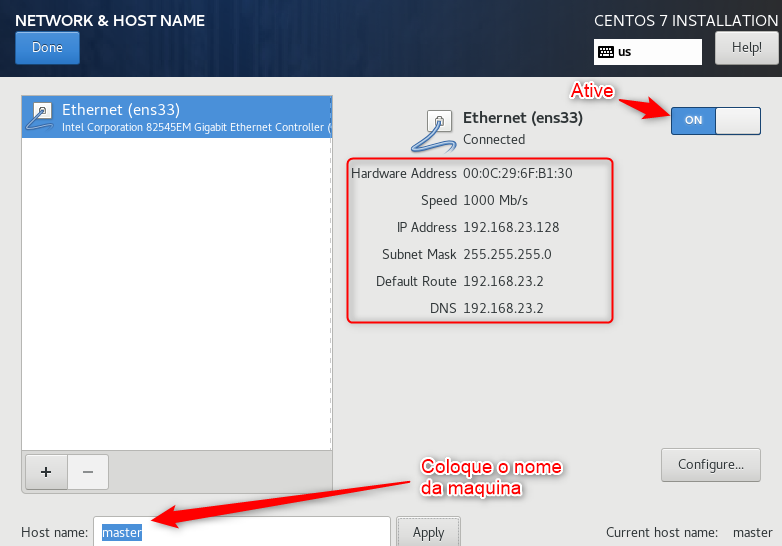 Configurando Network & Host Name
Configurando Network & Host Name
- Inicie a instalação e configure seu usuário e a senha do root do jeito que preferir!
Feito a instalação, vamos atualizar o nosso sistema!

Após realizar esse passo, vou dar uma tarefa para você, crie outras duas VMs com os mesmos passos descritos acima, lembrando que as próximas duas VMs não precisam da mesma configuração do que seu Master para este tutorial, no meu caso estou usando:
- CONFIGURAÇÕES MASTER: 64G HD, 4G RAM.
- CONFIGURAÇÃO 2 SLAVES: 20HD, 2G RAM.
- Nas outras maquinas, coloque outros nomes em HOST Name, estarei coloquando slave1, slave2
Após ter criado as 2 outras VMs, slave1 e slave2, atualize e de reboot nas 3 maquinas ja atualizadas, se quiser realize um backup das suas maquinas.
Agora inicie as 3 VMs e vamos começar a configurar nosso Apache Hadoop!
- Primeiramente precisamos pegar o IP das nossas maquinas então digite: ip addr show para buscar o ip.
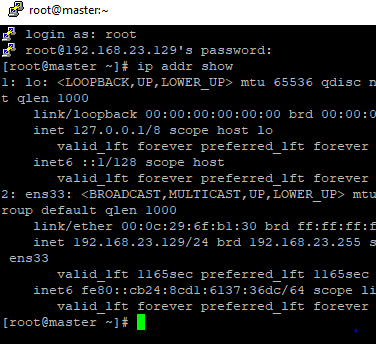
- Anote os ip das 3 maquinas e os nomes em um notepad que você ira precisar deles
Agora veja se o SSH está ativo, digite: systemctl status sshd.service
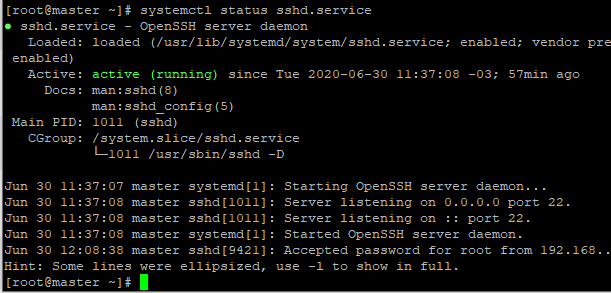
- Com isso você consegue acessar via ssh no seu computador se você estiver no Windows pode utilizar o Putty para fazer as conexões e ganhar em produtividade, lembrando que você deve deixar suas 3VMs minimizada para conseguir conectar.
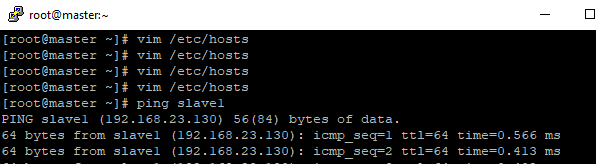
- Vamos configurar o arquivo hosts para conseguir acessar as maquinas pelo nome ao inves do endereço IP.
Digite: vi /etc/hosts e configure nas 3 maquinas, aperta a tecla I para editar o arquivo acrescente nas linhas abaixo o (IP da maquina) (nome da maquina), feito isso aperte a tecla ESC e :wq , para salvar e sair.
configurando slaves1 e slave2 no /etc/hosts do master

configurando master e slave2 no /etc/hosts do slave1

configurando master e slave1 no /etc/hosts do slave2

Agora digite ping (nome da maquina) e veja se está pingando em todas as maquinas.
Agora vamos realizar a instalação do JAVA!
- Primeiro vamos ir para o diretório aonde vamos organizar nossos downloads no meu caso eu uso o diretório /opt/
- Vamos instalar wget que é um programa que propicia o download de dados da web. Comando: yum install wget -y
- Vou fazer a instalação do JDK 8, que você pode encontrar para download AQUI
- Você pode ter a escolha de realizar a instalação ao invés de linha de comando realizar pelo WinSCP se desejar.
- O link que a gente utiliza é um pouco mais comprido pelo fato que você precisa logar na sua conta Oracle para realizar o download do aquivo e aceitar o termos de uso.
 fazendo download do jdk via wget
fazendo download do jdk via wget
- Feito o download note que já aparece o arquivo .tar.gz
- Para descompactar o arquivo vamos usar o comando: tar xzf jdk-8u251-linux-x64.tar.gz
 descompactando arquivo .tar
descompactando arquivo .tar
 Arquivo o jdk descompactado
Arquivo o jdk descompactado
- Após descompactar o aquivo vamos remover o arquivo .tar com comando rm jdk-8u251-linux-x64.tar.gz e vamos renomear o diretório para apenas jdk com o comando mv jdk1.8.0_251/ jdk.
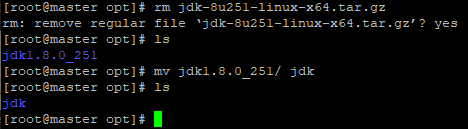 removendo o download do jdk e mudando o nome da pasta
removendo o download do jdk e mudando o nome da pasta
- Agora precisamos configurar o java nas variáveis de ambiente
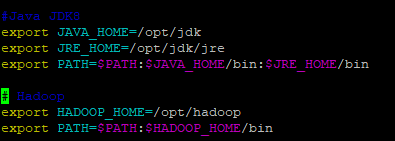
- Então de cd ~, para volta para o home e digite vim .bash_profile e configure as variáveis, I para editar, após configurar corretamente, ESC para sair do modo de edição :wq , para salvar e sair
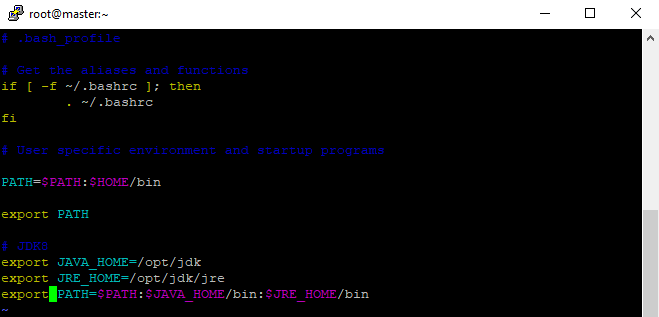 configurando variáveis de ambiente para o java
configurando variáveis de ambiente para o java
- Feito isso de um source .bash_profile para atualizar e java -version para ver se o java está instalado corretamente!
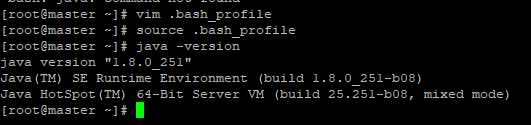 java instalado
java instalado
- Feito isso, repita o processo nas suas outras duas maquinas! e volte aqui para seguirmos a diante
Criando os usuários hadoop e realizando a configuração do SSH!
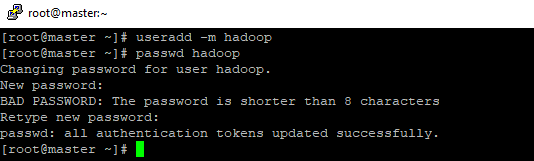
- Primeiramente vamos criar o usuário hadoop faça isso em todas as maquinas,
- Utilize o comando: useradd -m hadoop para criar o usuário e comando: passwd hadoop para definir uma senha para o usuário, se aparecer BAD PASSWORD mas você quiser continuar com a senha, basta repeti-la
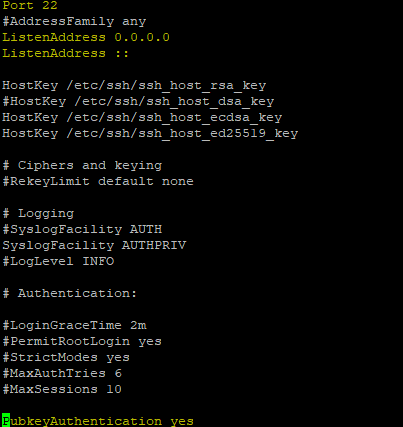
- Agora vamos configurar o SSH novamente nas 3 maquinas digite o comando: vim /etc/ssh/sshd_config
- No arquivo retire o # da porta, dos 2 ListenAddress e mais em baixo do PubkeyAuthentication, como no print abaixo
- Feito isso reinicie o serviço com comando: systemctl restart sshd.service
- Agora vamos criar a chave de segurança, isso vai permitir que as maquinas do nosso cluster consiga se conectar via SSH a outra maquina
- Agora vamos criar o arquivo de segurança COM O USUÁRIO HADOOP utilize o comando: su hadoop e va para diretório (~) home do usuário hadoop.
 entrando com usuário hadoop
entrando com usuário hadoop
- Vamos criar o arquivo de configuração APENAS NO NODE MASTER
- Para isso digite o comando ssh-keygen, aparecerá o arquivo se quiser manter o nome do arquivo basta dar enter, no meu caso eu vou mudar para /home/hadoop/.ssh/hadoop-key, precione ENTER duas vezes é resultado deve ser parecido com a imagem abaixo:
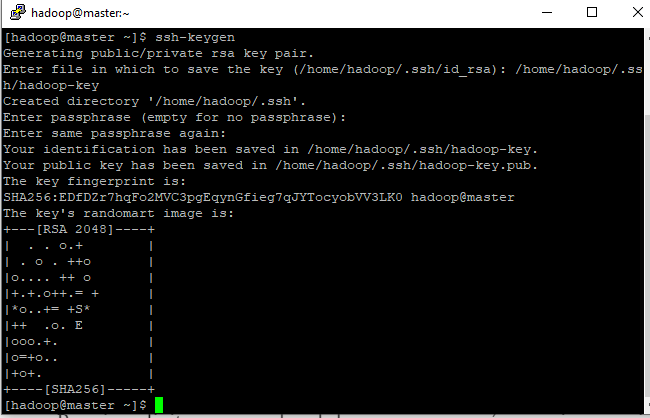 criando chave de ssh
criando chave de ssh
- Agora devemos copiar essa chave para as outras duas maquinas
- Para copiar a chave publica para os slaves devemos utilizar o comando : Digite: ssh-copy-id -i ~/.ssh/hadoop-key.pub hadoop@slave1
- Note que foi adicionado uma chave
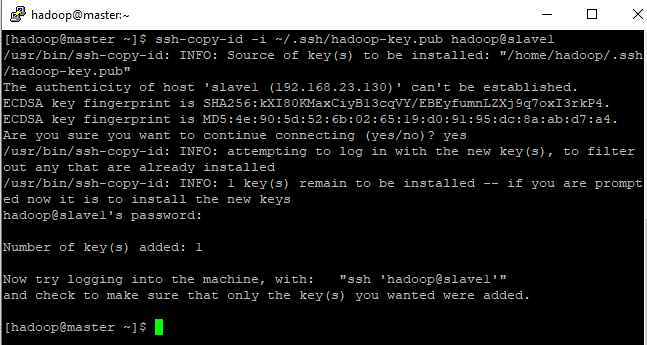 copiando chave publica do master para slave1
copiando chave publica do master para slave1
- Agora para conectar via SSH da master para o slave1 ou o slave2, basta utilizar o comando: ssh hadoop@slave1 -i ~/.ssh/hadoop-key
 entrando via ssh do master para slave1
entrando via ssh do master para slave1
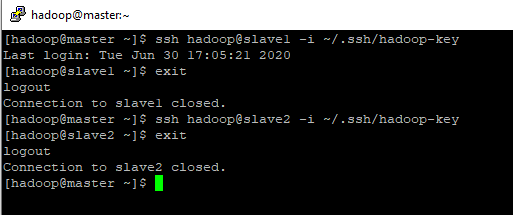 saindo do slave1 para master e conectando no slave2
saindo do slave1 para master e conectando no slave2
Realizando a instalação do Apache Hadoop
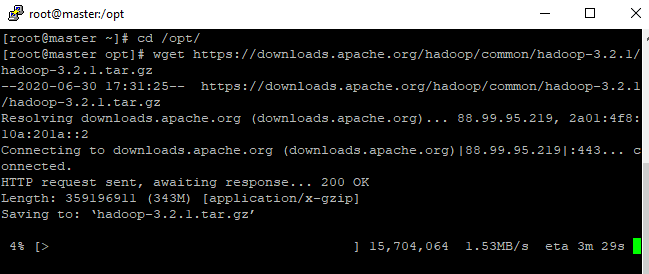
- Volte para o usuário root com o comando exit e vá para o site do hadoop clicando aqui, escolha a versão do hadoop que deseja, volte para o seu master e vá para o diretório /opt/ ou o diretório da sua preferencia e instale utilizando o comando wget!
- Após realizar o download descompacte o arquivo utilizando tar -xvf hadoop-(sua versão).tar.gz
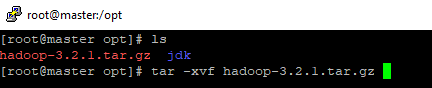
Apos descompactar vamos fazer a mesma coisa que fizemos com o java mude o nome do diretório para hadoop com comando: mv hadoop-3.2.1 hadoop e remova o arquivo .tar com comando rm hadoop-3.2.1.tar.gz.
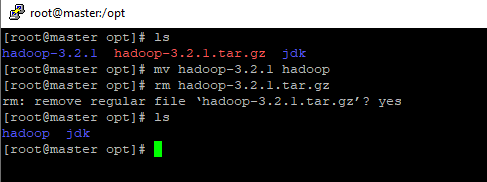 removendo e mudando nome do diretório hadoop
removendo e mudando nome do diretório hadoop
- Entre com usuário hadoop com comando su hadoop vá dentro do diretório hadoop em bin e verifique se versão está correta
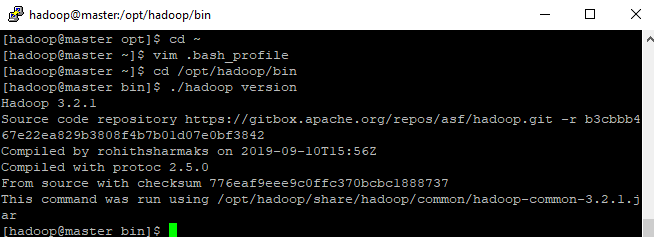
- Agora precisamos entrar com usuário hadoop e configurar as variáveis de ambiente, volte para o diretório home ~ e configure agora as variáveis para o hadoop, :wq para salvar e sair.
- Digite source .bash_profile para colocar as mudanças e digite hadoop version para ver se está devidamente configurado.
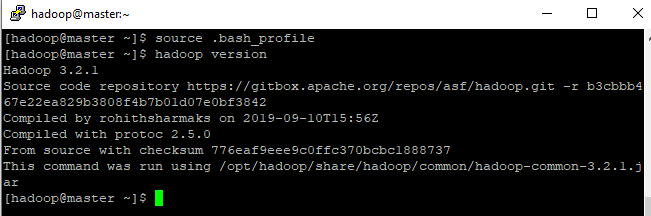
Configurando o Apache Hadoop
- De exit do usuário hadoop e entre novamente com o comando su — hadoop
- Agora vamos configurar alguns arquivos o PRIMEIRO deles é o arquivo hadoop-env-sh o caminho dele vim /opt/hadoop/etc/hadoop/hadoop-env.sh
- Aqui encontramos as variáveis do próprio hadoop
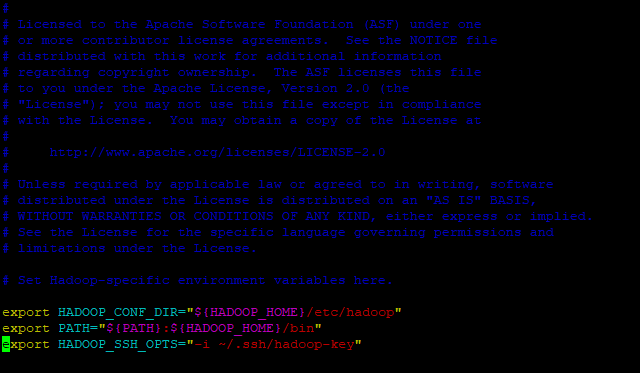 colocando variáveis dentro do arquivo hadoop env.sh
colocando variáveis dentro do arquivo hadoop env.sh
Acrescentando as linhas:
export HADOOP_CONF_DIR=”${HADOOP_HOME}/etc/hadoop”
export PATH=”${PATH}:${HADOOP_HOME}/bin”
(Coloque o nome da SUA chave de segurança)
export HADOOP_SSH_OPTS=”-i ~/.ssh/hadoop-key”
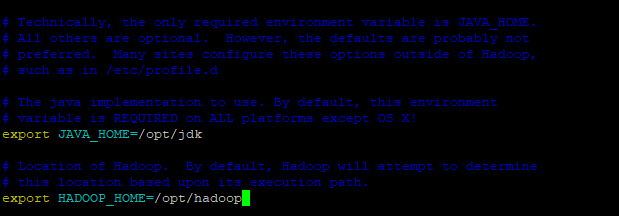
- Mais para baixo procure pela variável JAVA_HOME e HADOOP_HOME que estará comentada tire o # e coloque o caminho do diretório aonde se encontra o seu jdk e hadoop, no meu caso /opt/jdk e /opt/hadoop
- Segundo arquivo para gente configurar é o core-site.xml
Caminho vi /opt/hadoop/etc/hadoop/core-site.xml, note que está sem os parâmetros, vamos colocar um deles.
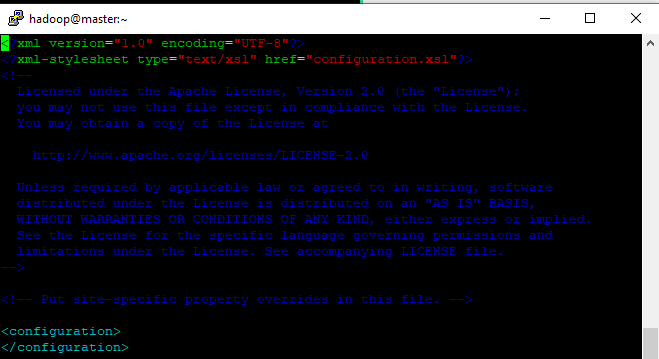 arquivo core-site.xml
arquivo core-site.xml
Acrescente as linhas:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:19000</value>
</property>
</configuration>
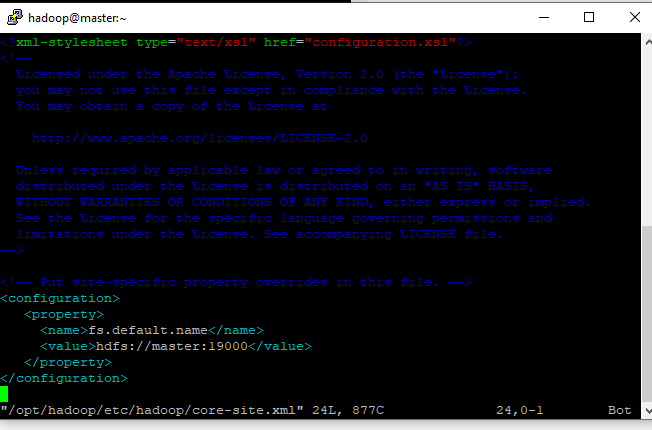 configurando core-site.xml
configurando core-site.xml
- Configure, salve e saia do arquivo.
- Crie os diretórios
mkdir /opt/hadoop/dfs
mkdir /opt/hadoop/dfs/data
mkdir /opt/hadoop/dfs/namespace_logs
- Feito isso, vamos configurar o arquivo aonde esses diretórios devem apontar no hdfs-site.xml
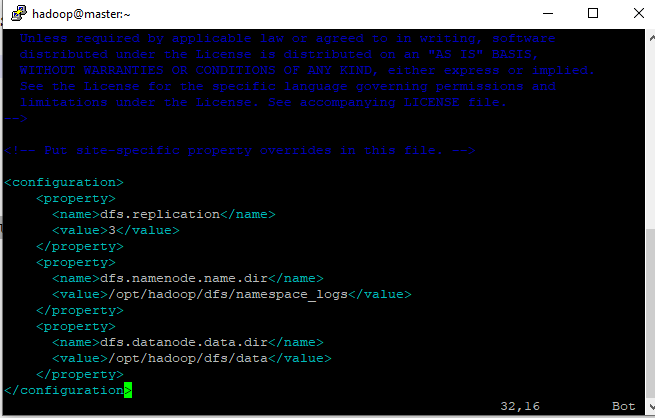 conf. hdfs-site.xml
conf. hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/dfs/namespace_logs</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/dfs/data</value>
</property>
</configuration>
- Agora precisamos mostrar quem serão nossos Datanodes / Workers caminho: vi /opt/hadoop/etc/hadoop/workers
- Retire o localhost e substitua pelo nome da maquina que você deu para os seus outros servidores no meu caso slave1 e slave2.
 configuração workers
configuração workers
- Próximo é a configuração do mapreduce, arquivo mapred-site.xml, caminho:vi /opt/hadoop/etc/hadoop/mapred-site.xml
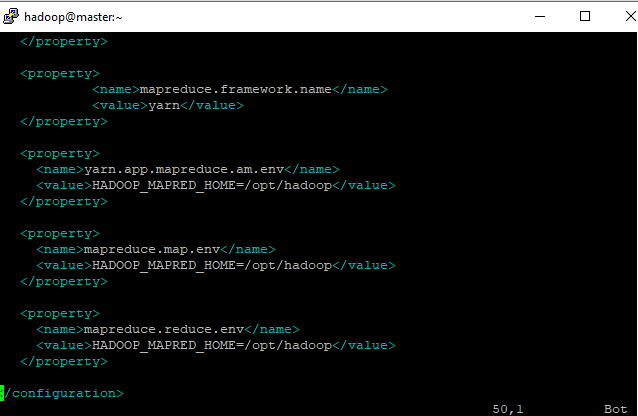 configuração mapred-site.xml
configuração mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.user.name</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
</configuration>
- Por ultimo, mas não menos importante o Yarn, caminho: vi /opt/hadoop/etc/hadoop/yarn-site.xml
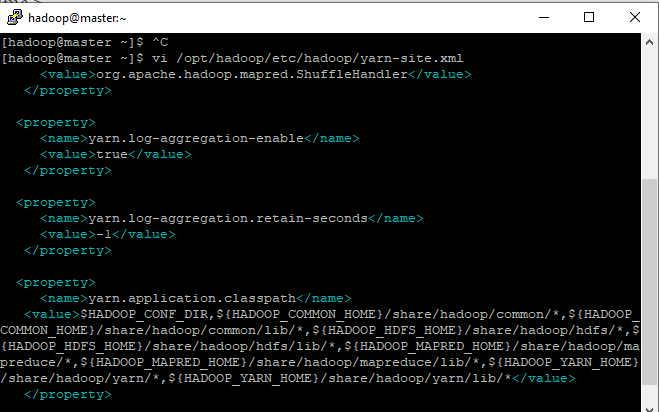 configuração yarn-site.xml
configuração yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.server.resourcemanager.application.expiry.interval</name>
<value>60000</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,${HADOOP_COMMON_HOME}/share/hadoop/common/*,${HADOOP_COMMON_HOME}/share/hadoop/common/lib/*,${HADOOP_HDFS_HOME}/share/hadoop/hdfs/*,${HADOOP_HDFS_HOME}/share/hadoop/hdfs/lib/*,${HADOOP_MAPRED_HOME}/share/hadoop/mapreduce/*,${HADOOP_MAPRED_HOME}/share/hadoop/mapreduce/lib/*,${HADOOP_YARN_HOME}/share/hadoop/yarn/*,${HADOOP_YARN_HOME}/share/hadoop/yarn/lib/*</value>
</property>
</configuration>
- Agora vamos copiar esses arquivos para os slave1 e para o slave2
- Primeiramente vamos entrar como root no slave1
- Vamos criar o hadoop
 criando diretório hadoop
criando diretório hadoop
- Note que esta com owner root, precisamos colocar o owner como usuário hadoop, com comando: chown -R hadoop:hadoop hadoop/
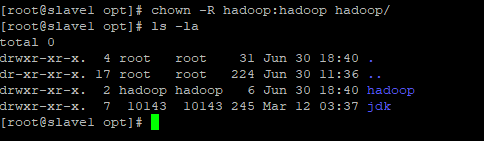 colocando owner o usuário hadoop
colocando owner o usuário hadoop
- Faça esse mesmo processo no slave1 e no slave2
- Volte para o master como usuário hadoop e copie os arquivos para os 2 slaves
scp -rv -i “~/.ssh/hadoop-key” /opt/hadoop hadoop@slave1:/opt
scp -rv -i “~/.ssh/hadoop-key” /opt/hadoop hadoop@slave2:/opt
Espere terminar, o Exit status deve ser = 0, se for algo diferente de 0 é porque teve problema na copia
 Exit status 0, tudo ok
Exit status 0, tudo ok
hadoop do slave1 copiado com sucesso!
Feito tudo isso o hadoop já está instalado e configurado, vamos iniciar ele!
- Com usuário hadoop no Master, vamos formatar o namenode:
su — hadoop
hdfs namenode -format
- Quando tiver formatando aparecera o log e você deve olhar pois não pode aparecer ERROR, caso apareça utilize o próprio log para fazer o troubleshooting
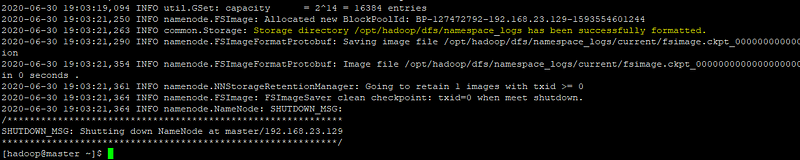
Devera aparecer Storage directory /opt/hadoop/dfs/namespace_logs has been successfully formatted.
- Isso quer dizer que ele está pronto para o uso, agora vamos inicializar o HDFS, digite: $HADOOP_HOME/sbin/start-dfs.sh
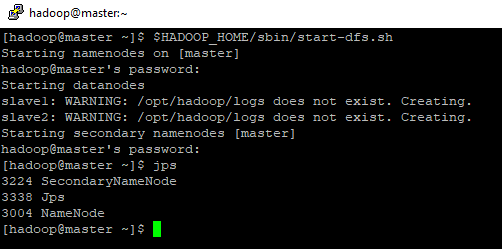 inicializando o hdfs
inicializando o hdfs
- Funcionou, vamos entrar no nosso cluster? para entrar da nossa maquina precisamos ver primeiramente se o firewall está ativo, digite: service firewalld status
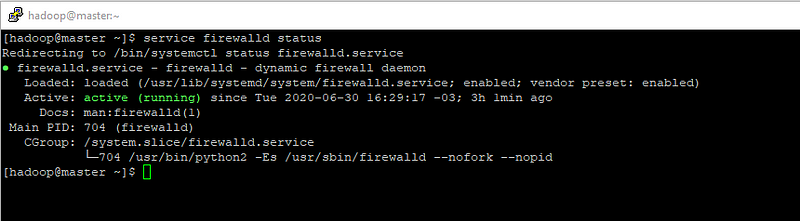 firewall ativo
firewall ativo
- Para parar o firewall digite : service firewalld stop
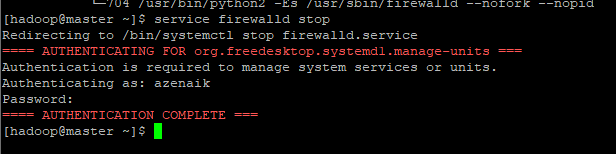
Agora na sua maquina local coloque o ip da sua maquina master na porta :9870
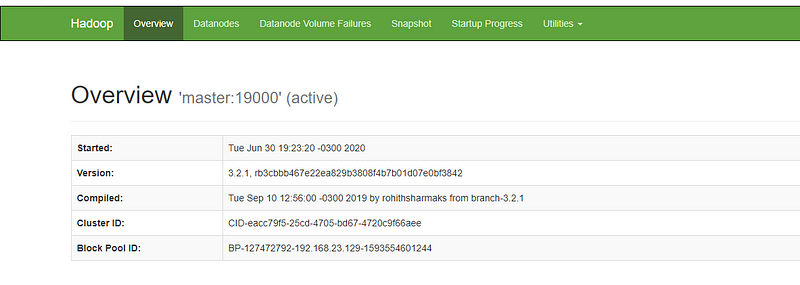 hadoop concluido
hadoop concluido
- Clicando em Datanodes vemos que os 2 slaves estão em execução!
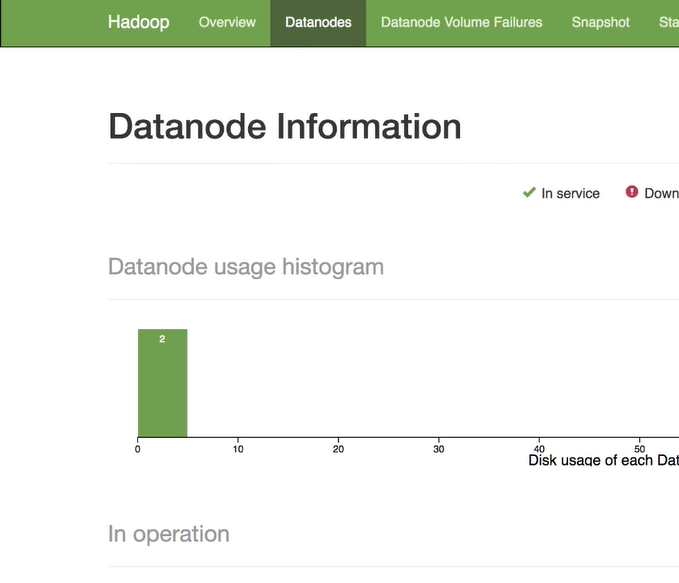
Agradeço quem chegou até aqui e espero que tenha ocorrido tudo bem nesse caminho, nesse tutorial embora simples espero que consiga ajudar você de alguma forma.






