


Interpretabilidade e Transparência de Modelos em Machine Learning
- #Machine Learning
- #Python
- #Inteligência Artificial (IA)
Nos últimos anos, o aprendizado de máquina (machine learning) tem desempenhado um papel central em diversas áreas, desde diagnósticos médicos até análise financeira. Contudo, a adoção em larga escala de modelos complexos, como redes neurais profundas e algoritmos ensemble com árvores de decisão, trouxe à tona preocupações quanto à sua compreensibilidade e confiabilidade. Dois conceitos fundamentais surgem como resposta a essas questões: interpretabilidade e transparência.
Mas o que é a interpretabilidade?
Interpretabilidade refere-se à capacidade de compreender como e por que um modelo de aprendizado de máquina chegou a determinada predição ou decisão.[3] Em termos práticos, um modelo interpretável é aquele cujas operações podem ser analisadas e explicadas em termos claros e intuitivos para um ser humano. Existe dois métodos de interpretabilidade[4]:
Local: Envolve a explicação de predições específicas. Por exemplo, por que um cliente foi aprovado para um empréstimo enquanto outro foi negado.
Global: Refere-se à compreensão geral de como o modelo funciona em todo o conjunto de dados, incluindo as relações que ele aprendeu entre variáveis.
Dessa forma, podemos entender a importância da interpretabilidade: com base na confiança, pois facilita a aceitação de sistemas baseados em IA ao permitir que os usuários compreendam suas decisões; por meio de diagnósticos, permitindo identificar erros, preconceitos e áreas de melhoria em modelos; e por fim em conformidade, atendendo às exigências regulatórias de transparência em setores como saúde e serviços financeiros.
Mas não podemos esquecer de um pilar complementar, a transparência, que está relacionada à capacidade de examinar as estruturas internas e o funcionamento de um modelo. Um modelo transparente é aquele cujo funcionamento é inerentemente claro sem a necessidade de ferramentas externas para interpretação. São exemplos de modelos transparentes: árvores de decisão, regressão linear e outros algoritmos simples. Nesse casos, sendo possível visualizar facilmente como uma entrada é transformada em saída.
Em paralelo existe os modelos opacos, que são difíceis de compreender justamente por mecanismos complexos internos, são alguns exemplos: Redes neurais profundas, algoritmos de boosting(combina um conjunto de aprendizes fracos em um aprendiz forte) e outros modelos complexos.
Pois bem, embora a interpretabilidade e transparência sejam desejáveis, muitas vezes há um trade-off entre esses conceitos e o desempenho do modelo. Modelos mais complexos tendem a ser mais precisos, mas menos interpretáveis.
E com isso, pode-se entender o que é XAI (Explainable Artificial Intelligence/Inteligência Artificial Explicável), certo?
Não? Ok, de acordo com a IBM, XAI é um conjunto de processos e métodos que permite aos usuários humanos compreender e confiar nos resultados e saídas criados por algoritmos de ML(Machine Learning/Aprendizado de Máquina).[1]
Em outras palavras, conforme artigo do Wikipedia, a XAI visa explicar o que foi feito, o que está sendo feito e o que será feito a seguir, e revelar em quais informações essas ações se baseiam. Isso torna possível confirmar o conhecimento existente, desafiar o conhecimento existente e gerar novas suposições.[2]
Quero compartilhar quatro abordagens para tornar o modelo mais interpretável:
- Modelos Simples: Sempre que possível, optar por modelos interiormente interpretáveis, como árvores de decisão ou regressão linear.
- Técnicas Pós-Hoc: No caso de modelos complexos, usar ferramentas: SHAP(O SHAP (SHapley Additive exPlanations) é baseado na teoria de jogos e calcula a contribuição de cada feature para a predição de um modelo, mostrando como cada variável impacta a saída.), LIME(O LIME (Local Interpretable Model-agnostic Explanations) aproxima o comportamento de um modelo complexo com um modelo mais simples e interpretável (como regressão linear) em uma região local, ao redor da predição que está sendo explicada.), Feature Importance(O método de Feature Importance atribui um score a cada variável, indicando o quão relevante ela é para o modelo na sua tarefa, podendo ser calculado de diversas formas de acordo com o modelo.), Interpret(A biblioteca Interpret oferece uma gama de modelos interpretáveis, incluindo o EBM, que permite obter explicações globais e locais sobre o comportamento do modelo.) e outros.
- Visualizações: Usar gráficos e dashboards para apresentar as explicações de forma intuitiva.
- Documentações: Registrar todo o processo de tomada de decisão do modelo e também as suposições feitas durante o treinamento.
Que tal ver um pouco de código?
Nos exemplos utilizei o Google Colab, que pode ser testado por aqui https://colab.new, utilisei o dataset Diabetes 2 do Kaggle, que pode ser baixado por aqui https://www.kaggle.com/datasets/cjboat/diabetes2
Exemplo de código com SHAP [5]
Agora, vamos usar a biblioteca SHAP para entender a importância de cada feature em nosso modelo XGBoost.
# O ambiente requer a instalação deste módulo
!pip install shap
# Importar as bibliotecas
import shap
import xgboost as xgb
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# Lendo o dataset
diabetes_data = pd.read_csv("/content/diabetes.csv")
# Separando Features e Variáveis Alvo
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Dividir os dados em treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Treinar um modelo XGBoost
model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100, max_depth=4)
model.fit(X_train, y_train)
# Criar um objeto SHAP
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)
# Capturando o nome das features
feature_names = list(X_train.columns)
# Visualizar a importância das features
shap.summary_plot(shap_values, X_test, feature_names=feature_names)
Neste código utilizamos o conjunto de dados Diabetes 2 para treinar um modelo XGBoost. Ele demonstra como usar a biblioteca SHAP para interpretar as predições do modelo, fornecendo insights sobre as variáveis mais importantes para as decisões tomadas.
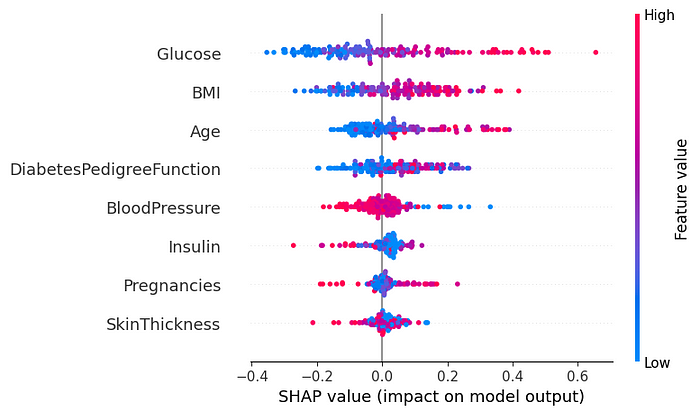
Saída do código acima shap.summary_plot
No gráfico SHAP, podemos observar que ‘Glucose’ e ‘BMI’ são as features que mais influenciam na decisão do modelo.
Exemplo de código com LIME [5]
Vamos agora demonstrar como o LIME pode explicar predições individuais de um modelo Random Forest.
# O ambiente requer a instalação deste módulo
!pip install lime
# Importar as bibliotecas
import numpy as np
import pandas as pd
import lime
import lime.lime_tabular
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Lendo o dataset
diabetes_data = pd.read_csv("/content/diabetes.csv")
# Separando Features e Variáveis Alvo
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Dividir os dados em treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Treinar um modelo Random Forest
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Capturando o nome das features
feature_names = list(X_train.columns)
# Criar um objeto LIME
explainer = LimeTabularExplainer(X_train.values,
feature_names=feature_names,
class_names=class_names,
mode='classification'
)
# Escolher uma instância para explicar
instance = X_test.values[10]
explanation = explainer.explain_instance(instance, model.predict_proba, num_features=6)
# Visualizar a explicação
explanation.show_in_notebook(show_table=True)
Neste exemplo utilizamos o conjunto de dados Diabetes 2 para treinar um modelo Random Forest, demonstrando como aplicar o LIME para gerar explicações locais para uma única instância de teste.
Na explicação, podemos ver que as features com valores positivos contribuíram para a previsão positiva, enquanto valores negativos contribuíram para a previsão negativa.

Saída do código acima explanation.show_in_notebook
explanation.as_list()

Saída do código acima explanation.as_list
Exemplo de código com Feature Importance
Utilizaremos o método Feature Importance para visualizar as variáveis mais relevantes para o modelo Random Forest.
# Importar as bibliotecas
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Lendo dataset
diabetes_data = pd.read_csv("/content/diabetes.csv")
# Separando Features e Variáveis Alvo
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Dividir os dados em treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Capturando o nome das features
feature_names = list(X_train.columns)
# Treinar um modelo Random Forest
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Obter a importância das features
importances = model.feature_importances_
# Criar um DataFrame para visualização
importance_df = pd.DataFrame({
'Feature': feature_names,
'Importance': importances
}).sort_values(by='Importance', ascending=False)
# Visualizar a importância das features
plt.figure(figsize=(10, 6))
plt.barh(importance_df['Feature'], importance_df['Importance'], color='skyblue')
plt.xlabel('Importância')
plt.ylabel('Feature')
plt.title('Importância das Features no Random Forest')
plt.gca().invert_yaxis()
plt.show()
Neste exemplo, utilizamos o conjunto de dados Diabetes 2 para treinar um modelo Random Forest. O código calcula a importância das variáveis e gera um gráfico de barras para ajudar na interpretação dos resultados.
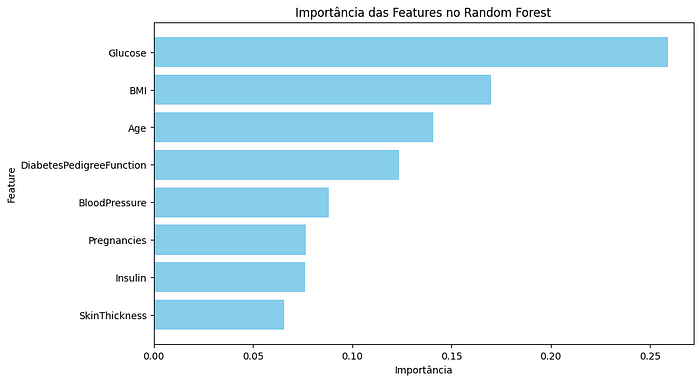
Importância das Features no Random Forest
O gráfico Feature Importance mostra que ‘Glucose’, ‘BMI’ e ‘Age’ são as variáveis mais importantes para o modelo Random Forest.
Exemplo de código com Interpret
Por fim, vamos usar a biblioteca Interpret para criar um modelo explicável e visualizar explicações globais e locais.
# O ambiente requer a instalação deste módulo
!pip install interpret
# Importar as bibliotecas
import numpy as np
import pandas as pd
from interpret.glassbox import ExplainableBoostingClassifier
from interpret import show
# Treinar um modelo interpretable
model = ExplainableBoostingClassifier()
model.fit(X_train, y_train)
# Gerar explicações
ebm_global = model.explain_global()
show(ebm_global)
# Explicação local para uma instância
instance = X_test.values[10]
ebm_local = model.explain_local(instance.reshape(1, -1), y_test[0:1])
show(ebm_local)
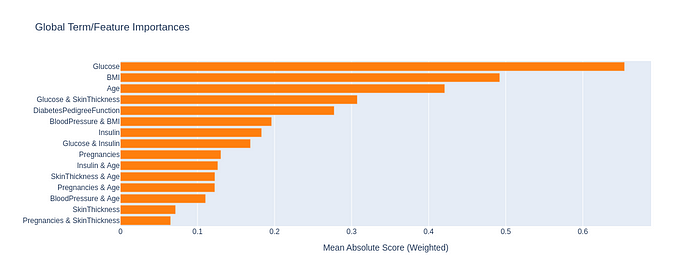
Global Term/Feature Importances
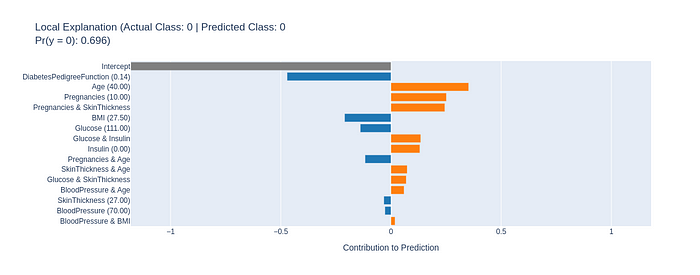
Local Explanation
Conclusão
O esforço em criar modelos interpretáveis é essencial para promover a confiança e a ética no uso da IA. Embora existam desafios a serem superados, como o trade-off entre precisão e interpretabilidade, o futuro do aprendizado de máquina certamente passa pela transparência e pela capacidade de explicar suas decisões.
Interpretabilidade e transparência não são apenas questões técnicas, mas também elementos fundamentais para aumentar a confiança, a ética e a eficiência dos sistemas de aprendizado de máquina. Ao investir em modelos explicáveis e transparentes, o profissional de ML não apenas melhora a aceitação por parte dos usuários, mas também garante que esses sistemas estejam alinhados às melhores práticas e às regulamentações vigentes.
Explore as ferramentas e técnicas apresentadas neste artigo, buscando não apenas precisão, mas também a compreensão de seus modelos.
Acredito que um futuro promissor para a IA passa pelo desenvolvimento de modelos que possamos não apenas usar, mas também entender.
Referências:
[3] https://www.dio.me/articles/interpretabilidade-em-modelos-de-machine-learning
[4] https://www.mathworks.com/discovery/interpretability.html
[5] https://www.datacamp.com/tutorial/explainable-ai-understanding-and-trusting-machine-learning-models

