



Data Warehouse e Data Lake: Quais as diferenças?
- #PostgreSQL
- #MySQL
- #MongoDB
No contexto da transformação digital nas empresas, a inteligência analítica tornou-se um dos principais pilares da gestão estratégica. Sobretudo na última década, a análise de big data desenvolveu-se a fim de acompanhar as rápidas mudanças do mercado – ocasionadas, entre outros fenômenos, pelo crescimento das redes sociais, do e-commerce e da tecnologia mobile.
Encarregadas de gerenciar e analisar dados corporativos, as equipes de big data e analytics buscam fomentar negócios competitivos e “à prova de futuro”. Para isso, contam com tecnologias cada vez mais sofisticadas de armazenamento e processamento de dados. Os data warehouses e data lakes estão entre as opções mais populares nesse sentido, cada qual com uma arquitetura e finalidade específica.
Vamos aprender mais sobre essas soluções, abordando pontos como:
- O que são data warehouses e data lakes;
- Quais as principais diferenças entre essas estruturas;
- Como cada repositório funciona;
- Como data warehouses e data lakes se inserem na rotina de business intelligence (BI).
A partir desta introdução, você terá insumos para iniciar ou aprimorar projetos de big data na sua empresa, atendendo às principais necessidades do seu negócio e derivando o máximo de valor dos dados coletados.
Classificação e Integração de Dados
Antes de apresentarmos os data warehouses e data lakes, precisamos falar sobre as categorias de dados e sobre o ETL, principal processo de integração de dados digitais. Acompanhe abaixo:
Tipos de Dados

Os dados disponíveis na web classificam-se hoje em três categorias:
Dados Estruturados
São dados formatados segundo parâmetros específicos, para organização em esquemas relacionais. Um dos principais formatos de dados estruturados são as tabelas, que os distribuem em linhas e colunas com valores pré-determinados.
Exemplos: planilhas eletrônicas e bancos de dados (arquivos do Excel, CSV, SQL, JSON, entre outros).≥÷
Dados Semiestruturados
Como o nome indica, são dados com alguma organização interna, mas que não são inteiramente estruturados.
Exemplos: arquivos da web (HTML, XML, OWL, entre outros).
Dados Não Estruturados
São dados sem uma organização ou hierarquia interna clara. É a categoria mais ampla, abrangendo a maior parte dos dados na web.
Exemplos: documentos de texto (arquivos do Word, PDFs), arquivos de mídia (imagem, áudio e vídeo), e-mails, mensagens de texto, dados de redes sociais, dispositivos móveis, Internet das Coisas (IoT), entre outros.
ETL
Em inglês, ETL é um acrônimo de Extract (Extrair), Transform (Transformar) e Load (Carregar).
O ETL é o método mais tradicional de integração de dados digitais, com cada termo da sigla designando uma etapa do processo. Observe o infográfico e leia mais abaixo:
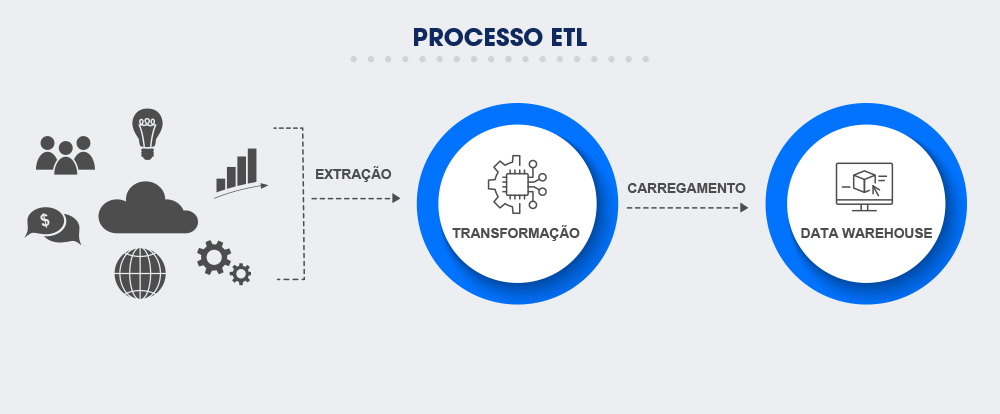
ETL: Como funciona o processo?
- Extração (E): nesta fase, os dados são coletados de diferentes sistemas organizacionais e conduzidos a um espaço temporário (staging area), onde são convertidos em um mesmo formato para transformação.
- Transformação (T): os dados brutos são lapidados e padronizados conforme as necessidades da empresa. Ao fim desta etapa, os dados estão “limpos”, estruturados e prontos para armazenamento.
- Carregamento (L): os dados tratados são enviados a um repositório específico, onde serão armazenados em segurança e acionados para consulta interna.
Desde o fim da década de 70, quando se popularizou, o ETL realiza a estruturação de dados para armazenamento em bancos como os data warehouses. Vamos saber mais sobre estes repositórios?
Data Warehouse
Como literais “armazéns de dados”, os data warehouses reúnem dados históricos para classificação em blocos semânticos, chamados relações. Por isso, o data warehouse é um banco de dados relacional, contendo principalmente dados estruturados.
Os dados do data warehouse são distribuídos em subconjuntos chamados data marts (“mercados de dados”), que agilizam a recuperação e entrega de dados para times específicos. Uma vez solicitados, os dados do data warehouse são disponibilizados em modo de leitura, conforme a demanda dos analistas de big data e BI.
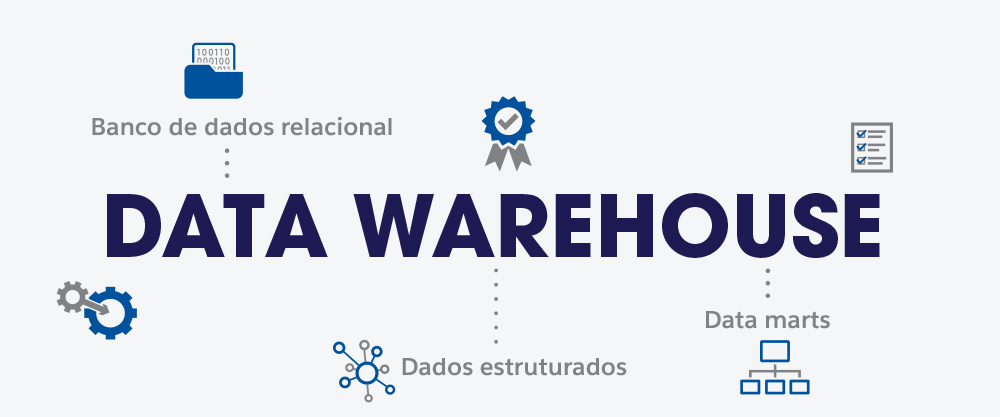
Unificados, livres de desvios e inconsistências, os dados do data warehouse rendem análises de alta precisão – que, por sua vez, geram informações e insights estratégicos. Resumindo, portanto: os data warehouses centralizam dados relevantes para a empresa, sistematizando-os de forma eficiente e apoiando a criação de estratégias data-driven de negócios.
Com um planejamento e ETL cuidadosos, os data warehouses agregam enorme valor às decisões organizacionais, sendo estruturas que permitem a otimização e aplicação prática dos dados armazenados.
Big Data e a Revolução dos Dados
Desde os anos 90, o uso comercial e doméstico da internet decolou, acelerando a geração e o tráfego de dados na web. Este fenômeno fez surgir o conceito de big data, revelando ainda as limitações dos data warehouses e de repositórios afins, como as bases de dados (databases).
Lidando com dados de volume, velocidade e variedade inéditas (os 3 Vs do big data), os gestores de tecnologia anteviram o colapso dos tradicionais sistemas de gestão da informação. Transformar dados para uso corporativo tornava-se uma operação muito cara: primeiro, por demandar milhares de terabytes de armazenamento (de dados que nem sempre eram pertinentes). Segundo, por tomar cada vez mais tempo das equipes dedicadas – exigindo, é claro, mão-de-obra qualificada.
Assim, tornar a gestão de dados mais eficiente, segura e economicamente sustentável era um desafio urgente para as empresas. No início dos anos 2000, surgiram os primeiros protótipos de uma solução inovadora: o data lake.
Data Lake
O que vem à sua mente ao pensar em um lago? Talvez a ideia de um grande reservatório natural, cuja água pode ser filtrada para abastecer o seu entorno. Essa metáfora – criada por James Dixon, um dos fundadores do Pentaho – ajuda a entender o conceito de data lake (“lago” ou reservatório de dados).
Ao contrário do data warehouse, o data lake é um banco de dados não relacional. Ou seja: trata-se de um repositório que não requer estruturação prévia dos dados, no qual estes “desembocam” em seu formato de origem (estruturado, semiestruturado ou não estruturado).
Uma vez derivados de sistemas e aplicações corporativas, os dados são conduzidos ao data lake “pulando” a etapa T do ETL (transformação). Sem este tratamento, o repositório armazena volumes gigantescos de dados de qualquer tipo e em qualquer escala, podendo chegar às centenas de petabytes (1 PB é mais de mil terabytes!).
Se o data lake é uma estrutura tão robusta, qual a vantagem de mantê-la? A de armazenar dados na íntegra e processá-los sob demanda, de forma escalável. A água do lago, por exemplo, pode ser filtrada para abastecer um caminhão-pipa ou garrafinhas de 500 ml. Da mesma forma, os dados do data lake (em grande parte não estruturados) são mais flexíveis, pois não foram enquadrados em esquemas pré-definidos.
Além de poupar tempo e custos de armazenamento, o data lake facilita a automação de processos e a inovação com base em dados, impulsionando a transformação digital das empresas. Os dados podem ser “customizados” para projetos de todas as áreas, além da criação de algoritmos de deep learning. Podem, ainda, serem estruturados para alocação em data warehouses, onde serão aproveitados em análises estratégicas.
Os data lakes são manejados principalmente por engenheiros e cientistas de dados, responsáveis por arquitetar a estrutura, integrá-la ao fluxo geral de dados e curar a grande riqueza de dados derivados. Em suma: é uma solução que gerencia dados de forma econômica e dinâmica, alinhando a empresa com as tendências do mercado contemporâneo.
Data Warehouse x Data Lake: Qual a melhor opção?
Enquanto ambos se prestam ao armazenamento e processamento de dados, os data warehouses e data lakes diferem entre si em quatro aspectos principais: conteúdo, função, usuários e tamanho.
Para escolher a melhor opção para o seu negócio, é preciso levar em conta critérios como o porte da empresa, os objetivos e as limitações de seus projetos de big data. Qual sua prioridade no momento: gerenciar dados com mais eficiência? Obter informações de inteligência de mercado? Ou fortalecer a área de inovação e soluções digitais?
Como regra, os data lakes são próprios para gerenciar dados não estruturados, e os data warehouses, essenciais para análises de grande escala. No entanto, vale lembrar que os repositórios não são excludentes. Quando integram o mesmo fluxo de gestão de dados, os data warehouses e data lakes combinam vantagens como aumento da produtividade, maior assertividade nas análises e melhor relação custo-benefício.
Por fim, outro ponto a ser avaliado é o modelo de armazenamento – local (on-premises), na nuvem (cloud) ou híbrido. O armazenamento na nuvem tem se popularizado pela escalabilidade e baixo custo, já que não requer integração com sistemas locais. Engenheiros de dados e outros especialistas podem orientar você e sua equipe para planejar o arranjo mais seguro e funcional para sua empresa.








