

Transfer Learning
- #Python
- #Machine Learning
# Seja bem vindo !
Olá, Sou Flayson Santos Machine Learning Specialist
**Github** Transfer_Learning_Horses_vs_Humans
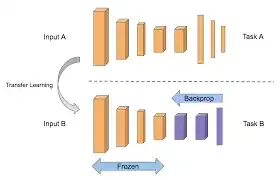
Neste projeto iremos trabalha com Transfer Learning (aprendizagem por transferência) com tensorflow com dataset inception v3.
Esta projeto será aplicar as tecnicas abaixo sobre Transfer Learning onde iremos aumentar a precisão do treinamento para Cavalos x Humanos. Para evitar overfitting louco, a precisão do seu conjunto de validação deve ser de cerca de 95% .
Vamos la baixe o notebook abra no colab ou no jupyter notebook
### Compreendendo a aprendizagem por transferência conceitos:
*E se você pudesse pegar um modelo existente que é treinado em muito mais dados e usar os recursos que esse modelo aprendeu?*
Esse é o conceito de aprendizagem de transferência.
Então, por exemplo, se você visualizar seu modelo assim com uma série de camadas convolucionais antes de camada densa levar sua camada de saída, você alimenta seus dados para a camada superior, a rede aprende as convoluções que identificam as feições em seus dados e tudo isso.
Mas considere o modelo de outra pessoa, talvez um que seja muito mais sofisticado que o seu, treinado em muito mais dados.
Eles têm camadas convolucionais e estão aqui intactos com feições que já foram aprendidas.
Assim, você pode bloqueá-los em vez de treiná-los novamente em seus dados, e fazer com que eles apenas extraiam os recursos de seus dados usando as convoluções que eles já aprenderam.
Em seguida, você pode pegar um modelo que foi treinado em um conjunto de dados muito grandes e usar as convoluções que ele aprendeu ao classificar seus dados.
Se você se lembrar de como as convoluções são criadas e usadas para identificar feições específicas e a jornada de uma feição através da rede, faz sentido usá-las e, em seguida, retreinar as camadas densas desse modelo com seus dados.
Claro, bem, é típico que você possa bloquear todas as convoluções, Você não precisa.
Você pode optar por treinar novamente alguns dos mais baixos também porque eles podem ser muito especializados para as imagens em mãos.
É preciso alguma tentativa e erro para descobrir a combinação certa. Então vamos pegar um modelo bem treinado de última geração. Há um chamado Inception, que você pode aprender mais sobre em seu [site](https://arxiv.org/abs/1512.00567).
Isso foi pré-treinado em um conjunto de dados do ImageNet, que tem 1,4 milhões de imagens em 1000 classes diferentes.
## Codificação
Então vamos dar uma olhada em como conseguiríamos isso em código. Vamos começar com as entradas. Em particular, vamos usar a API keras layers, para escolher as camadas, e para entender quais queremos usar, e quais queremos treinar novamente. Uma cópia dos pesos pré-treinados para a rede neural inicial é salva neste URL. Pense nisso como um instantâneo do modelo depois de ser treinado. São os parâmetros que podem ser carregados no esqueleto do modelo, para transformá-lo em um modelo treinado. Então, agora, se quisermos usar o início, é uma sorte que o keras tenha a definição do modelo incorporada. Então você instancia isso com a forma de entrada desejada para seus dados e especifica que você não deseja usar os pesos internos, mas o instantâneo que você acabou de baixar. O início V3 tem uma camada totalmente conectada na parte superior. Então, definindo include_top como false, você está especificando que deseja ignorar isso e ir direto para as convoluções. Agora que eu tenho meu modelo pré-treinado instanciado, eu posso iterar através de suas camadas e bloqueá-los, dizendo que eles não serão treináveis com este código.
import os
from tensorflow.keras import layers
from tensorflow.keras import Model*
dataset [inception v3](https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels)
*from tensorflow.keras.applications.inception_v3 import InceptionV3
local_weights_file = '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
pre_trained_model = InceptionV3(input_shape = (150, 150, 3),
include_top = False,
weights = None)
pre_trained_model.load_weights(local_weights_file)
for layer in pre_trained_model.layers:
layer.trainable = False
pre_trained_model.summary()*
Adicionando seu Deep Neural Network (DNN)
Na codificação , vimos como pegar as camadas de um modelo existente e criá-las para que não sejam retreinadas -- ou seja, podemos congela (ou bloqueia) as convoluções já aprendidas em seu modelo. Agora, vamos adicionar nossa próprio DNN na parte inferior deles, que pode ser treinado novamente para nossos dados.
Codificando nosso próprio modelo com recursos transferidos
Todas as camadas têm nomes, para que possamos procurar o nome da última camada que desejamos usar. Se inspecionarmos o resumo, veremos que as camadas inferiores se dividiram para 3 por 3. Mas eu quero usar algo com um pouco mais de informação. Então eu movi para cima a descrição do modelo para encontrar mixed7, que é a saída de um monte de convolução que são 7 por 7. podemos não querer usar esta camada e é divertido experimentar com os outros. Mas com este código, eu vou pegar essa camada desde o início e levá-la para a saída.
*last_layer = pre_trained_model.get_layer('mixed7')
last_output = last_layer.output*
______________________________________________________________________
Então agora vamos definir nosso novo modelo, tomando a saída da camada mixed7 do modelo inicial, que tínhamos chamado last_ouput. Isso deve se parecer exatamente com os modelos densos que você criou no início deste curso. O código é um pouco diferente, mas esta é apenas uma maneira diferente de usar a API de camadas. Você começa achatando a entrada, que apenas acontece de ser a saída desde o início. E, em seguida, adicione uma camada oculta densa. E então sua camada de saída que tem apenas um neurônio ativado por um sigmóide para classificar entre dois itens. Em seguida, você pode criar um modelo usando a classe abstrato modelo. E passando para a entrada e a definição de camadas que você acabou de criar.
E então você compilá-lo como antes com um otimizador e uma função de perda e as métricas que você deseja coletar.
*from tensorflow.keras.optimizers import RMSprop
x = layers.Flatten()(last_output)
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dense (1, activation='sigmoid')(x)
model = Model( pre_trained_model.input, x)
model.compile(optimizer = RMSprop(learning_rate=0.0001),
loss = 'binary_crossen*
____________________________________________________________________
**Adicione nossos parâmetros de aumento de dados ao ImageDataGenerator**
*train_datagen = ImageDataGenerator(rescale = 1./255.,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
train_generator = train_datagen.flow_from_directory(
train_dir,
batch_size = 20,
class_mode = 'binary',
target_size = (150, 150))
**Chamos o treinamento do modelo com a função model.fit**
history = model.fit(
train_generator,
validation_data = validation_generator,
steps_per_epoch = 100,
epochs = 100,
validation_steps = 50,
verbose = 2)*
_______________________________________________________________________
## Explorando abandonos
Há outra camada em Keras chamada de abandono. E a ideia por trás do abandono é que camadas em uma rede neural às vezes podem acabar tendo pesos semelhantes e possíveis impactos entre si levando ao excesso de ajuste. Com um modelo complexo como este, é um risco.
Então, como conseguiremos isso em código? Bem, aqui está a nossa definição de modelo . E aqui é onde adicionamos o abandono. O parâmetro está entre 0 e 1 e é a fração de unidades a serem descartadas.
*from tensorflow.keras.optimizers import RMSprop
x = layers.Flatten()(last_output)
x = layers.Dense(1024, activation='relu')(x)
**x = layers.Dropout(0.2)(x)**
x = layers.Dense (1, activation='sigmoid')(x)
model = Model( pre_trained_model.input, x)
model.compile(optimizer = RMSprop(lr=0.0001),
loss = 'binary_crossentropy',
metrics = ['acc'])*
Neste caso, estamos a retirar 20% dos nossos neurônios. Para comparação, aqui no notebook voce pode conferir o gráfico de treinamento contra a precisão de antes do abandono ser adicionado. Quando você vê a validação divergir do treinamento como este ao longo do tempo, é realmente um ótimo candidato para tentar usar um abandono.
_____________________________________________________________________


