


Tipos de Sistemas Distribuídos Comparativo entre algumas arquiteturas e o middleware
Aqui temos os tipos de arquiteturas adotadas em projetos de sistemas distribuídos tais como os modelos de sistemas de computação distribuída, sistemas de informação distribuídos e os sistemas distribuídos pervasivos. Para cada um destes modelos distribuídos, veremos as seguintes arquiteturas:
- Computação em Cluster
- Computação em Grade
- Sistemas de Processamento de Transações
- Integração de Aplicações Empresariais
- Computação em Nuvem
- Arquitetura Orientada a Serviços (SOA)
- Computação Pervasiva
- Computação Orientada a Transações
- Redes de Sensores
Sistemas de Computação Distribuída
Os sistemas de computação distribuída são modelos projetados com objetivos de compartilhamento de recursos, desempenho, confiabilidade, tolerância a falhas e escalabilidade. Dessa forma, a computação distribuída visa acrescentar o número de réplicas (cópias) de processadores disponíveis na rede para atender aos objetivos do sistema.
A seguir, veremos os modelos de computação distribuída denominados por Cluster e Grade.
Computação em Cluster
A computação em cluster é um modelo de computação distribuída de alto desempenho, mas com restrições bem definidas em sua configuração e arquitetura. Tais restrições determinam que seja o mesmo sistema operacional em todos os computadores, hardwares semelhantes e sejam configurados em uma rede local de alta velocidade.Isto é, trata-se de um ambiente computacional homogêneo. A sua popularização se deu a partir da melhoria no desempenho dos computadores pessoais e a redução do seu custo de aquisição.
O cluster é formado por um computador mestre (nó mestre) que é o responsável pelo controle, envio de tarefas e o efetivo balanceamento de carga dos computadores escravos (nós escravos). Dessa forma, o nó mestre possui um serviço de gerenciamento do cluster, bibliotecas para programação paralela e o seu sistema operacional local. Os nós escravos possuem os componentes do serviço de processamento paralelo e o seu sistema operacional local.
Para sua adoção efetiva visando os ganhos em desempenho, confiabilidade, escalabilidade e tolerância a falhas, a aplicação (sistema de informação) que executará sobre o cluster deverá ser programado de tal maneira que possa consumir os recursos do cluster. Isto é, cada tarefa será inicializada por um usuário diferente através da aplicação, poderá ser executada paralelamente em cada nó escravo. Por exemplo, um usuário A solicita um relatório, o usuário B solicita uma alteração de telefone e o usuário C solicita uma exclusão de dados. Cada uma destas tarefas poderão ser executadas em três processadores ou nós diferentes.

O cluster Newton pode atingir uma performance teórica de pico de 13 TFlop/s (FLoating-point Operations Per Second - Operações de Ponto Flutuante por Segundo) ou Trilhões de Cálculos Matemáticos por Segundo.
No site Top500 (www.top500.org), são realizadas análises semestrais de desempenho dos supercomputadores ao redor do mundo. Na lista do ranking dos três melhores pontuados, encontramos os supercomputadores com o pico teórico de 44 PFlop/s (TIANHE-2), 18 PFlop/s (TITAN - CRAY XK7) e 17 PFlop/s (SEQUOIA - BLUEGENE/Q). Apesar da performance surpreendente do TIANHE-2, o mesmo foi projetado para alcançar a performance teórica de 54 TFlop/s. Em todos os casos, o sistema operacional que executava em todos os computadores da lista é baseado no GNU/Linux.
O maior supercomputador brasileiro é o Cray XT6 do INPE (Instituto Nacional de Pesquisas Espaciais) atinge a performance teórica de pico de 258 TFlop/s, mas com desempenho efetivo (real) de 17 TFlop/s.

O cluster Altix (Figura 3) pode atingir uma performance teórica de pico de 16 TFlop/s.

Computação em Grade (Grid Computing)
Com o crescimento da Internet, do número de sites e aplicações móveis e ubíquas, e do número de serviços oferecidos na Web, proporcionalmente o número de usuários também cresceu. Isso quer dizer que muitos usuários distantes geograficamente estão acessando aplicações distribuídas, mas que ainda estão muito longe deles. A distância numa rede que sofre com picos de congestionamento em determinados horários é um fator que deve ser levado em consideração. Quanto mais distante os usuários estão dos recursos computacionais que dão suporte às aplicações, maior será a latência da rede. Em outras palavras, o tempo de resposta (TR) será maior e causará impaciência aos usuários, podendo levar a aplicação ao total descrédito. Em termos mais técnicos e discutidos anteriormente, as aplicações com problemas de TR poderão ficar indisponíveis resultando em problemas de confiabilidade e desempenho de devido ao aumento contínuo da concorrência.
A computação em grade ou em grelha é um modelo de computação distribuída de alto desempenho. O modelo propõe a configuração de organizações virtuais (OV) ou federações. Em cada OV contém um grupo de servidores dedicados para executar tarefas da localidade em questão. Assim, o modelo permite a configuração em rede de longa distância e não tem restrições quanto ao hardware, sistema operacional e rede. Isto é, trata-se de um ambiente computacional heterogêneo.
Alinhado ao problema inicial deste tópico, veja que a Figura 4 mostra o modelo da grade JPPF (JavaParallel Processing Framework - Framework em Java para Processamento Paralelo) contendo três JPPF Servers. Cada JPPF Server e os Nodes (nós) formam uma OV, resultando num modelo de rede P2P e Cliente/Servidor com escalonamento de recursos de processamento. Além disso, esta grade aberta é desenvolvida em Java e pode ser executada em sistemas operacionais baseados no Unix, GNU/Linux e Windows, o que garante maior portabilidade da solução. Se o acesso a esta grade for através de Web Services (WS), qualquer aplicação - independentemente da linguagem de programação que dê suporte ao WS - poderá acessar aos recursos de processamento paralelo da grade. Isso garante maior portabilidade, compartilhamento de recursos e distribuição da solução.

Computação em Nuvem (Cloud Computing)
A computação em nuvem é um modelo de arquitetura distribuída que oferece um ambiente de serviços de infraestrutura e de sistemas computacionais. A ideia inicial da nuvem veio para propor serviços limitados aos usuários que desejavam armazenar e acessar documentos e arquivos de áudio/vídeo através da Internet. Com a disseminação da nuvem, atualmente ela abrange também serviços de infraestrutura e desenvolvimento de sistemas que são cobrados mediante o uso destes recursos de tecnologia da informação.
Para lidar com diferentes nichos de mercado e usuários, o projeto das nuvens foi revisto quanto a sua infraestrutura e formas de utilização e pagamento. Dessa forma, a estrutura de serviços foi dividida em três camadas que atendem a diversos usuários e empresas da seguinte maneira:
- Software as a Service (SaaS) - Software como um Serviço: Camada de software que oferece aplicativos aos usuários tais como webmail, aplicativos de áudio, vídeo e armazenamento de dados.
- Plataform as a Service (PaaS) - Plataforma como um Serviço: Camada para o ambiente de desenvolvimento de sistemas. Possui frameworks para desenvolvimento de software e sistemas gerenciadores de bancos de dados.
- Infraestructure as a Service (IaaS) - Infraestrutura como um Serviço: Camada para a virtualização de hardware, sistemas operacionais, relatórios gerenciais e dispositivos de armazenamento de dados (storages).
A Figura mostra os diferentes serviços e usuários consumidores para demonstrar o que discutimos acima.
A Figura demonstra o acesso de usuários (à esquerda) aos recursos e serviços da nuvem (à direita). Os usuários utilizam, em sua grande maioria, serviços do SaaS para ter acessos aos aplicativos disponíveis na nuvem.
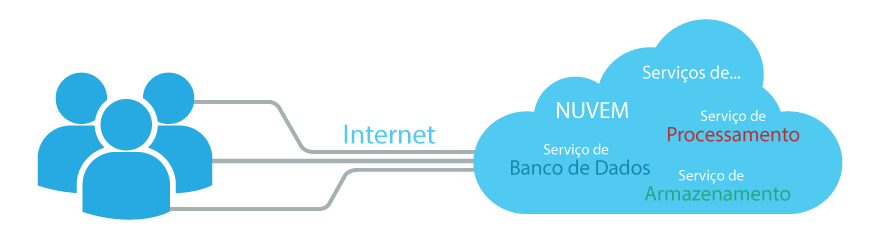
Estrutura da computação em nuvem e a comunicação com instituições
Fonte: GUIMARÃES, Leandro; CORRÊA, Matheus; OSÓRIO, Tomás. Computação em Nuvem.
Arquitetura Orientada a Serviços (Service-oriented Architecture - SOA)
A arquitetura orientada a serviços é um novo paradigma no desenvolvimento de soluções em software, pois apresenta uma proposta de interoperabilidade e acoplamento fraco de serviços. Estes serviços podem ser entendidos como um ou mais métodos disponíveis ou um processo grande em execução. Estes serviços são unidades básicas e fundamentais para o desenvolvimento de software. Além disso, utilizam padrões e protocolos de comunicação abertos, como, por exemplo, o HiperText Transfer Protocol (HTTP). Assim, os serviços viabilizam a comunicação entre os departamentos de uma empresa ou entre empresas diferentes que possuem algum tipo de parceria de negócios.
A arquitetura orientada a serviços deve possuir um barramento de serviços (Enterprise Service Bus - ESB) onde cada serviço deve ter uma interface de comunicação que fornece a assinatura. Esta assinatura deve conter os parâmetros de entrada e saída, tratamentos de erro e tipos de mensagens padronizadas. A Figura demonstra a estrutura básica da arquitetura SOA contendo os sistemas de informação (SI), o barramento ou camada de serviços (ESB) e a camada de bancos de dados (BD). Na camada de SI, temos um exemplo de sistemas para os departamentos de uma empresa (Marketing, Recursos Humanos, Financeiro, Departamento Pessoal etc.). Na camada ESB, temos os serviços de software (regras de negócio) e serviços de dados (objetos de banco de dados, conexões, acesso a dados etc.). Na camada de BD, temos dados de diversos assuntos importantes para os departamentos, tais como ativos, clientes, fornecedores, produtos etc.
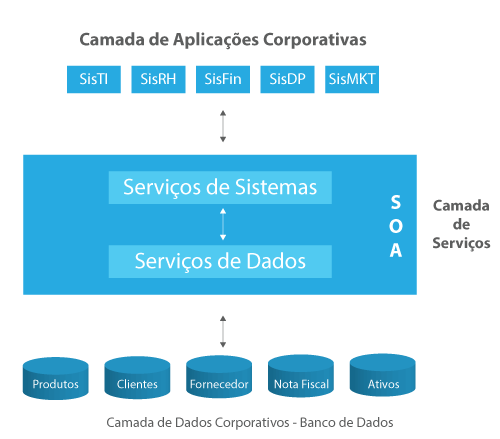
Estrutura básica da Arquitetura Orientada a Serviços






