



Revisão do Modulo PostgreSQL
- #PostgreSQL
Este artigo é referente ao módulo "Conceitos e Melhores Práticas com Bancos de Dados PostgreSQL", ministrado pelo Professor Daniel Costa, o qual mostrou um vasto domínio sobre a ferramenta.
Dediquei alguns dias revendo os conceitos abordados no módulo, pesquisando na documentação e condensando as nove horas de aula neste artigo e devo dizer que foi particularmente desafiador e muito construtivo escrevê-lo então se você gostou, não deixe de marcar o artigo como útil.
Por meio do mesmo, venho citar os pontos chaves abordados na aula como forma de fixar o que foi aprendido e servir de guia para todos os interessados em rever os conceitos por trás deste módulo. Caso eu aborde algum conceito de forma errônea, por favor me avisem para que eu possa corrigir.
Introdução ao banco de dados PostgreSQL
O PostgreSQL é um SGBD relacional OpenSource que teve início no departamento de ciência da computação na Universidade da Califórnia em Berkeley em 1986.
Para iniciarmos, precisamos entender que o PostgreSQL utiliza o modelo relacional de dados. Mas o que seria um modelo relacional?
É o modelo mais comum no mercado. Ele busca classificar e organizar as informações com linhas(também chamadas de tuplas) e colunas. As colunas são os campos onde ficam os atributos de uma informação e as linhas guardam os valores dessas informações. Estas informações são guardadas em tabelas.
Ainda dentro do modelo relacional, temos algumas colunas muito importantes e rotineiras na vida de quem trabalha com banco de dados em geral, sendo elas a chave primária(Primary Key) e a chave estrangeira(Foreign Key).
- Chave Primária: Muitas vezes referenciada apenas como PK, é um conjunto de campos que nunca se repetem. Este campo é a identidade de uma tabela, qual pode ser composto por um único atributo ou pela composição de vários. Sua utilização se da através da referenciação na criação de relacionamentos entre tabelas.
- Chave Estrangeira: Muitas vezes referenciada apenas como FK, este campo é utilizado como referência para outra tabela, criando um relacionamento entre tabelas.
O que pode ser definido como tabela?
- Coisas tangíveis como: elementos físicos(carro, produto, animal)
- Funções como : perfis de usuários, status de uma compra e etc.
- Eventos ou Ocorrências: Produtos de um pedido, histórico de dados.
SGBD
O PostgresSQL é um SGBD, assim como o MySql, SQLServer, MongoDB, entre outros. Mas o que a sigla SGBD significa?
Definição: SGBD é a sigla para Sistemas de Gerenciamento de Banco de Dados, que são conjunto de softwares responsáveis pelo gerenciamento de um banco de dados. Neste conjunto de softwares existem programas que facilitam a administração de um banco de dados.
Principais Características do PostgresSQL
- OpenSource
- Point in time recovery
- Linguagem procedural com suporte a várias linguagens de programação(perl, python, entre outras)
- Views, functions, procedures, triggers
- Consultas complexas e Common table expressions(CTE)
- Suporte a dados geográficos(PostGIS)
- Controle de concorrência multi-versão
Instalação
Obs: Quando o banco é instalado também é criado por padrão um cluster(Agrupamento de banco de dados que possuem as mesmas configurações).
Objetos e tipos de dados do PostgreSQL
Para começar a entender melhor o PostgreSQL, devemos conhecer seus arquivos de configurações, tais como: postgresql.conf, pg_hba.conf, pg_ident.conf e os comandos administrativos. Por padrão, estes arquivos encontram-se dentro do diretório PGDATA definido no momento da inicialização do cluster de banco de dados(se instalado no diretório padrão eles devem estar em : C:\Program Files\PostgreSQL\suaVersaoDoPostgre\data).
- O arquivo postgresql.conf
- Aqui estão definidas e armazenadas todas as configurações do servidor PostgreSQL. Alguns desses parâmetros só podem ser alterados com uma reinicialização do banco de dados(No windows devemos reiniciar o Serviço
- postgresql-x64-11). Através da view pg_settings, podemos acessar todas as configurações atuais.
- Para isso usamos a instrução:
SELECT name, setting From pg_settings;
ou
SHOW [parametro]
Parâmetros encontrados dentro do postgresql.conf


- O arquivo pg_hba.conf
- É o arquivo responsável por controlar a autenticação dos usuários no servidor PostgreSQL.
- Seus métodos de Autenticação são:

- O arquivo pg_ident.conf
- É o arquivo responsável por mapear os usuários do sistema operacional com os usuários do banco de dados. Para poder ser utilizado, a opção ident no arquivo pg_hba.conf deve estar habilitada.
- Comandos Administrativos
- Para acessar de forma mais fácil os comandos administrativos no Windows, precisamos adicionar os binários do PostgreSQL ao PATH do sistema.
- Primeiro abrimos o gerenciador de arquivos e clicamos com o botão direito do mouse sobre "Este Computador" e clicamos em propriedades.

Depois selecionamos "Configurações Avançadas do Sistema"

Clicamos em "Variáveis de Ambiente".

Clicamos sobre "Path" e clicamos em Editar.

Clicamos em novo adicionamos o caminho da pasta onde estão os binários do PostgreSQL.

Clicamos em "Ok" e agora os comandos funcionaram no terminal do Windows.
Agora poderemos executar comandos como:
- createdb
- createuser
- dropdb
- initdb
- pg_ctl
- pg_basebackup
- pg_dump / pg_dumpall
- pg_restore
- psql
- reindexdb
- vacuumdb
Comandos para o binário psql
psql -U postgres -> Acessa o psql atraves do usuário padrão do postgre
psql -U nome_usuario password senha_usuario -> Acessa o psql através de login e senha
psql -p numero_da_porta -> tenta conectar ao banco de dados pela porta informada
psql -h endereco_IP_host -> passa o endereço ip do host
Os comandos acima também podem ser combinados:
psql -h localhost -U username databasename
Arquitetura / Hierarquia
- Cluster
- É uma coleção de bando de dados que compartilham as mesmas configurações(arquivos de configuração) do PostgreSQL e do sistema operacional(portam listen_adresses, etc).
- Banco de dados (database)
- São conjunto de schemas com seus objetos/relações (tabelas, funções, views, etc). Seus schemas e objetos não podem ser compartilhados entre si. Cada database é separado do outro compartilhando apenas usuários, roles e configurações do cluster PostgreSQL.
- Schema
- São conjunto de objetos/relações (tabelas, funções, views, etc). É possível relacionar objetos entre diversos schemas.
- Objetos
- São tabelas, views, funções, types, sequences, entre outros. São pertencentes ao Schema.
Tipos de Dados
O postgreSQL tem uma lista bem extensa de tipos de dados, tanto para números como para caracteres. Para conhecer todos eles você pode checar a Documentação.
Ferramenta PGAdmin
- Importante para Conexão
- Liberar acesso ao cluster em postgresql.conf
- Liberar acesso ao cluster para o usuário do banco de dados em pg_hba.conf
- Criar/editar usuários
Conceitos user/roles/groups
Roles (papéis ou funções), users (usuários) e grupo de usuários são "contas", perfis de atuação em um banco de dados, que possuem permissões em comum ou específicas.
*É possível que roles pertençam a outras roles.
Quando é dito que uma role pertence a outra role com a opção INHERIT marcada, ela herda as permissões da role "pai".

Para criar uma role com opções utiliza-se o comando:
CREATE ROLE name [ [ WITH ] option [ ... ] ]
Para alterar uma Role utilizamos o comando:
ALTER ROLE role_specification [ WHIT ] option [ ...]
Para excluir uma role utilizamos o comando:
DROP ROLE role_specification;
Onde as opções podem ser:


Exemplos de criação/Alteração/Deleção de roles utilizados na aula:
CREATE ROLE professores NOCREATEDB NOCREATEROLE INHERIT NOLOGIN NOBYPASSRLS CONNECTION LIMIT 10;
Alter ROLE professores PASSWORD '123';
CREATE ROLE daniel LOGIN PASSWORD '123';
DROP ROLE daniel;
CREATE ROLE daniel LOGIN PASSWORD '123' IN ROLE professores;
DROP ROLE daniel;
CREATE Role daniel LOGIN PASSWORD '123' ROLE professores;
DROP ROLE daniel;
Outros comandos para roles
- REVOKE : Desassocia membros entre roles
REVOKE [role que será revogada] FROM [role que terá suas permissões revogadas]
Exemplo:
REVOKE professores FROM daniel;
- GRANT : Associa uma role a outra.
GRANT [role a ser concedida] TO [role a assumir as permissões]
Exemplo:
GRANT professores TO daniel;
Utilizando GRANT e REVOKE para administrar DATABASES, SCHEMAS e TABLES
Os dois comando citados cima também podem ser utilizados para administrarem os objetos do PostgreSQL
GRANT
- Para DATABASES:
GRANT { { CREATE | CONNECT | TEMPORARY | TEMP } [, ...] | ALL [ PRIVILEGES ] }
ON DATABASE database_name [, ...]
TO role_specification [, ...] [ WITH GRANT OPTION ]
- Para SCHEMAS:
GRANT { { CREATE | USAGE } [, ...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
TO role_specification [, ...] [ WITH GRANT OPTION ]
- Para Tabelas:
GRANT { { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON { [ TABLE ] table_name [, ...]
| ALL TABLES IN SCHEMA schema_name [, ...] }
TO role_specification [, ...] [ WITH GRANT OPTION ]
REVOKE
- Para DATABASES:
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | CONNECT | TEMPORARY | TEMP } [, ...] | ALL [ PRIVILEGES ] }
ON DATABASE database_name [, ...]
FROM role_specification [, ...]
[ CASCADE | RESTRICT ]
Revogando em todos os DATABASES:
REVOKE ALL ON ALL DATABASE [database] FROM [role];
- Para SCHEMAS:
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON { { FUNCTION | PROCEDURE | ROUTINE } function_name [ ( [ [ argmode ] [ arg_name ] arg_type [, ...] ] ) ] [, ...]
| ALL { FUNCTIONS | PROCEDURES | ROUTINES } IN SCHEMA schema_name [, ...] }
FROM role_specification [, ...]
[ CASCADE | RESTRICT ]
Revogando em todos os SCHEMAS:
REVOKE ALL ON ALL SCHEMA [schema] FROM [role];
- Para Tabelas:
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON { [ TABLE ] table_name [, ...]
| ALL TABLES IN SCHEMA schema_name [, ...] }
FROM role_specification [, ...]
[ CASCADE | RESTRICT ]
Revogando em todas as Tableas:
REVOKE ALL ON ALL TABLES IN SCHEMA [schema] FROM [role];
DML e DDL
Antes de definir estes dois termos, gostaria de abordar algo muito frisado na aula que é o conceito de Idempotência que é a propriedade que algumas ações/operações possuem possibilitando-as de serem executadas diversas vezes sem alterar o resultado após a aplicação inicial. Exemplos de Idempotência são : IF NOT EXISTS, IF EXISTS, WHERE NOT EXISTS, WHERE EXISTS.
Para poder seguir com excelência os pontos deste artigo, recomenda-se que acesse o GitHub do professor para ter acesso aos comandos de DML e DDL, afim de termos as mesmas informações no nosso banco de dados PostgreSQL.
DML (Data Manipulation Language)
- Também conhecido como CRUD(Create, Read, Update, Delete). Englobam os comandos de INSERT, UPDATE, DELETE e para alguns autores também o SELECT.
INSERT : Insere dados em uma tabela:
INSERT INTO [nome da tabela] ([campos da tabela,])
VALUES ([valores de acordo com a ordem dos campos acima,]);
Exemplo com Idempotência:
INSERT INTO agencia (banco_numero,numero,nome)
SELECT 341,1,'Centro da cidade'
WHERE NOT EXISTS (SELECT banco_numero,numero,nome FROM agencia WHERE banco_numero = 341 AND nome = 'Centro da cidade');
Exemplo com ON CONFLICT(Se tiver conflito, não faz nada)
INSERT INTO agencia (banco_numero,numero,nome) VALUES (341,1,'Centro da cidade') ON CONFLICT (banco_numero,numero) DO NOTHING;
UPDATE : Atualiza dados em uma tabela(*Cuidado ao utilizar este comando!)
UPDATE [nome da tabela] SET
[campo1] = [novo valor do campo1],
[campo2] = [novo valor do campo2],
...
[campoN] = [novo valor do campoN]
[WHERE + condições];
* Sempre utilize o WHERE para especificar o registro a ser alterado.
DELETE : Deleta os dados de uma tabela(Cuidado com este comando!)
DELETE FROM [nome da tabela]
[WHERE + condições];
* Sempre utilize o WHERE para especificar o registro a ser alterado.
SELECT : Seleciona os dados
SELECT [campos da tabela]
FROM [nome da tabela]
[WHERE + condições]
* Como boa pratica, evite sempre que puder o SELECT * em Querys por uma questão de performace
WHERE (coluna/condição)
= , > / >= , < / <= , <> / != , LIKE , ILIKE , IN
onde:
LIKE possui case sensitive
e
ILIKE não possui case sensitive
- Primeira condição sempre WHERE, demais condições, AND e OR.
- Comandos utilizados na aula:
SELECT numero, nome, ativo FROM banco;
SELECT banco_numero, numero, nome FROM agencia;
SELECT numero, nome, email FROM cliente;
SELECT id, nome FROM tipo_transacao;
SELECt banco_numero, agencia_numero, numero, cliente_numero FROM conta_corrente;
SELECT banco_numero, agencia_numero, cliente_numero FROM cliente_transacoes;
SELECT * FROM cliente_transacoes;
CREATE TABLE IF NOT EXISTS teste (
id SERIAL PRIMARY KEY,
nome VARCHAR(50) NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
DROP TABLE IF EXISTS teste;
CREATE TABLE IF NOT EXISTS teste (
cpf VARCHAR(11) NOT NULL,
nome VARCHAR(50) NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (cpf)
);
INSERT INTO teste (cpf, nome, created_at)
VALUES ('22344566712','José Colméia','2019-07-01 12:00:00');
-- Inserção para dar erro
INSERT INTO teste (cpf, nome, created_at)
VALUES ('22344566712','José Colméia','2019-07-01 12:00:00');
INSERT INTO teste (cpf, nome, created_at)
VALUES ('22344566712','José Colméia','2019-07-01 12:00:00') ON CONFLICT (cpf) DO NOTHING;
UPDATE teste SET nome = 'Pedro Alvares' WHERE cpf = '22344566712';
SELECT * FROM teste;
DDL(Data Definition Language)
- Englobam os comandos de CREATE, ALTER e DROP.
CREATE : Cria um objeto podendo ser um : DATABASE, SCHEMA , TABLE, entre outros.
- DATABASES:
CREATE DATABASE name
[ [ WITH ] [ OWNER [=] user_name ]
[ TEMPLATE [=] template ]
[ ENCODING [=] encoding ]
[ LC_COLLATE [=] lc_collate ]
[ LC_CTYPE [=] lc_ctype ]
[ TABLESPACE [=] tablespace_name ]
[ ALLOW_CONNECTIONS [=] allowconn ]
[ CONNECTION LIMIT [=] connlimit ]
[ IS_TEMPLATE [=] istemplate ] ]
- SCHEMAS:
CREATE SCHEMA schema_name [ AUTHORIZATION role_specification ] [ schema_element [ ... ] ]
CREATE SCHEMA AUTHORIZATION role_specification [ schema_element [ ... ] ]
Melhores Práticas:
CREATE SCHEMA IF NOT EXISTS schema_name [ AUTHORIZATION role_specification ]
CREATE SCHEMA IF NOT EXISTS AUTHORIZATION role_specification
- TABLES:
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE table_name ( [
{ column_name data_type [ COLLATE collation ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE source_table [ like_option ... ] }
[, ... ]
] )
Melhores Práticas: Utilizar o IF NOT EXISTS.
CREATE TABLE IF NOT EXISTS table_name(
column_name data_type [ COLLATE collation ] [ column_constraint [ ... ]
)
ALTER: Altera um objeto
- DATABASES:
ALTER DATABASE name RENAME TO new_name
ALTER DATABASE name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
- SCHEMAS:
ALTER SCHEMA name RENAME TO new_name
ALTER SCHEMA name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
- TABLES:
ALTER TABLE [ IF EXISTS ] [ ONLY ] name [ * ]
action [, ... ]
ALTER TABLE [ IF EXISTS ] [ ONLY ] name [ * ]
RENAME [ COLUMN ] column_name TO new_column_name
ALTER TABLE [ IF EXISTS ] [ ONLY ] name [ * ]
RENAME CONSTRAINT constraint_name TO new_constraint_name
ALTER TABLE [ IF EXISTS ] name
RENAME TO new_name
ALTER TABLE [ IF EXISTS ] name
SET SCHEMA new_schema
DROP
- DATABASES:
DROP DATABASE [ IF EXISTS ] name
- SCHEMAS:
DROP SCHEMA [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
- TABLES:
DROP TABLE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
Comandos DDL utilizados na aula:
-- CRIAR UM DATABASE (QUERY TOOL)
CREATE DATABASE financas;
-- CRIAR UMA TABELA NO SCHEMA (QUERY TOOL) (TRABALHAR NO PUBLIC)
CREATE TABLE IF NOT EXISTS banco (
numero INTEGER NOT NULL,
nome VARCHAR(50) NOT NULL,
ativo BOOLEAN NOT NULL DEFAULT TRUE,
data_criacao TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (numero)
);
CREATE TABLE IF NOT EXISTS agencia (
banco_numero INTEGER NOT NULL,
numero INTEGER NOT NULL,
nome VARCHAR(80) NOT NULL,
ativo BOOLEAN NOT NULL DEFAULT TRUE,
data_criacao TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (banco_numero,numero),
FOREIGN KEY (banco_numero) REFERENCES banco (numero)
);
CREATE TABLE cliente (
numero BIGSERIAL PRIMARY KEY,
nome VARCHAR(120) NOT NULL,
email VARCHAR(250) not null,
ativo BOOLEAN NOT NULL DEFAULT TRUE,
data_criacao TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE conta_corrente (
banco_numero INTEGER NOT NULL,
agencia_numero INTEGER NOT NULL,
numero BIGINT NOT NULL,
digito SMALLINT NOT NULL,
cliente_numero BIGINT NOT NULL,
ativo BOOLEAN NOT NULL DEFAULT TRUE,
data_criacao TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (banco_numero,agencia_numero,numero,digito,cliente_numero)
FOREIGN KEY (banco_numero,agencia_numero) REFERENCES agencia (banco_numero,numero),
FOREIGN KEY (cliente_numero) REFERENCES cliente (numero)
);
CREATE TABLE tipo_transacao (
id SMALLSERIAL PRIMARY KEY,
nome VARCHAR(50) NOT NULL,
ativo BOOLEAN NOT NULL DEFAULT TRUE,
data_criacao TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE cliente_transacoes (
id BIGSERIAL PRIMARY KEY,
banco_numero INTEGER NOT NULL,
agencia_numero INTEGER NOT NULL,
conta_corrente_numero BIGINT NOT NULL,
conta_corrente_digito SMALLINT NOT NULL,
cliente_numero BIGINT NOT NULL,
tipo_transacao_id SMALLINT NOT NULL,
valor NUMERIC(15,2) NOT NULL,
data_criacao TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (banco_numero,agencia_numero,conta_corrente_numero,conta_corrente_digito,cliente_numero) REFERENCES conta_corrente(banco_numero,agencia_numero,numero,digito,cliente_numero)
);
Melhores práticas em DDL
- Importante as tabelas possuírem campos que realmente serão utilizados e que sirvam de atributo direto a um objetivo em comum.
- Criar/Acrescentar colunas que são "atributos básicos" do objeto:
- Exemplo: tabela CLIENTE: coluna TELEFONE / coluna AGENCIA_BANCARIA
- Cuidado com regras (constraints)
- Cuidado com o excesso de FKs
- Cuidado com o tamanho indevido de colunas
- Exemplo: coluna CEP VARCHAR(255)
TRUNCATE
- Comando para esvaziar uma tabela e/ou resetar o IDENTITY da tabela.
TRUNCATE [ TABLE ] [ ONLY ] name [ * ] [ , ... ] [ RESTART IDENTITY | CONTINUE IDENTITY ] [ CASCADE | RESTRICT ]
Funções Agregadas
Uma função de agregação computa um único resultado para várias linhas de entrada. Por exemplo, existem funções de agregação para contar (count), somar (sum), calcular a média (avg), o valor máximo (max) e o valor mínimo (min) para um conjunto de linhas.
- AVG
- Faz a média dos valores de um campo de entrada
SELECT AVG(campo) FROM table_name;
- COUNT
- Faz a contagem do numero de campos
SELECT COUNT(campo) FROM table_name;
- MAX
- Mostra o maior valor dentre os campos
SELECT MAX(campo) FROM table_name;
- MIN
- Mostra o menor valor dentre os campos
SELECT MIN(campo) FROM table_name;
- SUM
- Exibe o somatório dos campos
SELECT SUM(campo) FROM table_name;
Clausula GROUP BY
Não podemos falar de agregação sem citar a clausula GROUP BY. Ela irá colapsar em uma única linha todas as linhas que tem os mesmos valores para a expressão agrupada.
Exemplo feito na aula:
SELECT COUNT(id), tipo_transacao_id
FROM cliente_transacoes
GROUP BY tipo_transacao_id;
A query acima trará o seguinte resultado:

Aqui estamos fazendo a contagem de cada id(COUNT(id)) e dizendo quantas vezes esse id aparece para cada campo tipo_transacao_id através da clausula GROUP BY (GROUP BY tipo_transacao_id).
Quando se faz uma seleção de dados utilizando uma função de agregação junto da seleção de outro parâmetro como no exemplo acima, se faz necessário a utilização da clausula GROUP BY para que o banco saiba sobre qual atributo ele deve agrupar os dados.
Comandos escritos durante a aula :
SELECT * FROM information_schema.columns
WHERE table_name = 'banco';
SELECT column_name, data_type FROM information_schema.columns
WHERE table_name = 'banco';
SELECT valor FROM cliente_transacoes;
SELECT AVG(valor) FROM cliente_transacoes;
SELECT COUNT(numero)
FROM cliente;
-- Código com erro
SELECT COUNT(numero), email
FROM cliente
WHERE email ILIKE 'gmail.com';
-- Código correto
SELECT COUNT(numero), email
FROM cliente
WHERE email ILIKE 'gmail.com'
GROUP BY email;
SELECT MAX(numero)
FROM cliente;
SELECT MIN(numero)
FROM cliente;
SELECT MAX(valor)
FROM cliente_transacoes;
SELECT MIN(valor)
FROM cliente_transacoes;
SELECT MAX(valor), tipo_transacao_id
FROM cliente_transacoes
GROUP BY tipo_transacao_id;
SELECT MIN(valor)
FROM cliente_transacoes
GROUP BY tipo_transacao_id;
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'banco';
SELECT COUNT(id), tipo_transacao_id
FROM cliente_transacoes
GROUP BY tipo_transacao_id;
SELECT COUNT(id), tipo_transacao_id
FROM cliente_transacoes
GROUP BY tipo_transacao_id
HAVING COUNT(id) > 150;
SELECT SUM(valor)
FROM cliente_transacoes;
SELECT SUM(valor), tipo_transacao_id
FROM cliente_transacoes
GROUP By tipo_transacao_id;
SELECT SUM(valor), tipo_transacao_id
FROM cliente_transacoes
GROUP BY tipo_transacao_id
ORDER BY tipo_transacao_id ASC;
SELECT SUM(valor), tipo_transacao_id
FROM cliente_transacoes
GROUP BY tipo_transacao_id
ORDER BY tipo_transacao_id DESC;
JOINS
Um dos tópicos mais importantes dentro de qualquer banco de dados relacional, o famoso e algumas vezes assustador JOIN. Nada mais é do que uma clausula de junção de tabelas. Para começar entender JOINS devemos pensar na Teorias dos conjuntos.

- JOIN ou INNER JOIN
- Retorna o valor comum entre duas tabelas através de uma chave em comum:

SELECT tabela_1.campos, tabela_2.campos
FROM tabela_1
JOIN tabela_2 ON tabela_2.campo = tabela_1.campo
*A Clausula ON diz através de qual campo as tabelas serão "juntadas" ou unidas.
- LEFT JOIN (OUTER)
- Tem como resultado todos os registros que estão na tabela A (mesmo que não estejam na tabela B) e os registros da tabela B que são comuns à tabela A. Como o próprio nome já diz(Left), a tabela A sempre será a da esquerda.

SELECT tabela_1.campos, tabela_2.campos
FROM tabela_1
LEFT JOIN tabela_2 ON tabela_2.campo = tabela_1.campo
- RIGHT JOIN (OUTER)
- Usando o Right Join, teremos como resultado todos os registros que estão na tabela B (mesmo que não estejam na tabela A) e os registros da tabela A que são comuns à tabela B, onde a tabela B será sempre a da direita.

SELECT tabela_1.campos, tabela_2.campos
FROM tabela_1
RIGHT JOIN tabela_2 ON tabela_2.campo = tabela_1.campo
- FULL JOIN (OUTER)
- Tem como resultado todos os registros que estão na tabela A e todos os registros da tabela B.
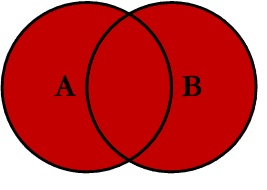
SELECT tabela_1.campos, tabela_2.campos
FROM tabela_1
FULL JOIN tabela_2 ON tabela_2.campo = tabela_1.campo
- CROSS JOIN
- Este comando cruza todos os dados das tabelas, gerando uma matriz.
SELECT tabela_1.campos, tabela_2.campos
FROM tabela_1
CROSS JOIN tabela_2
Comandos utilizados nas aulas:
SELECT numero, nome FROM banco;
SELECT banco_numero, numero, nome FROM agencia;
SELECT numero, nome FROM cliente;
SELECT banco_numero, agencia_numero, numero, digito, cliente_numero FROM conta_corrente;
SELECT id, nome FROM tipo_transacao;
SELECT banco_numero, agencia_numero, conta_corrente_numero, conta_corrente_digito, cliente_numero, valor FROM cliente_transacoes;
SELECT count(1) FROM banco; -- 151
SELECT count(1) FROM agencia; -- 296
-- 296
SELECT banco.numero, banco.nome, agencia.numero, agencia.nome
FROM banco
JOIN agencia ON agencia.banco_numero = banco.numero;
SELECT count(banco.numero)
FROM banco
JOIN agencia ON agencia.banco_numero = banco.numero;
SELECT banco.numero
FROM banco
JOIN agencia ON agencia.banco_numero = banco.numero
GROUP BY banco.numero;
SELECT count(distinct banco.numero)
FROM banco
JOIN agencia ON agencia.banco_numero = banco.numero;
SELECT banco.numero, banco.nome, agencia.numero, agencia.nome
FROM banco
LEFT JOIN agencia ON agencia.banco_numero = banco.numero;
SELECT agencia.numero, agencia.nome, banco.nome
FROM agencia
RIGHT JOIN banco ON banco.numero = agencia.banco_numero;
SELECT agencia.numero, agencia.nome, banco.numero, banco.nome
FROM agencia
LEFT JOIN banco ON banco.numero = agencia.banco_numero;
SELECT banco.numero, banco.nome, agencia.numero, agencia.nome
FROM banco
FULL JOIN agencia ON agencia.banco_numero = banco.numero;
CREATE TABLE IF NOT EXISTS teste_a (id SERIAL PRIMARY KEY, valor VARCHAR(10));
CREATE TABLE IF NOT EXISTS teste_b (id SERIAL PRIMARY KEY, valor VARCHAR(10));
INSERT INTO teste_a (valor) VALUES ('teste1');
INSERT INTO teste_a (valor) VALUES ('teste2');
INSERT INTO teste_a (valor) VALUES ('teste3');
INSERT INTO teste_a (valor) VALUES ('teste4');
INSERT INTO teste_b (valor) VALUES ('teste_a');
INSERT INTO teste_b (valor) VALUES ('teste_b');
INSERT INTO teste_b (valor) VALUES ('teste_c');
INSERT INTO teste_b (valor) VALUES ('teste_d');
SELECT tbla.valor, tblb.valor
FROM teste_a tbla
CROSS JOIN teste_b tblb;
DROP TABLE IF EXISTS teste_a;
DROP TABLE IF EXISTS teste_b;
SELECT banco.nome,
agencia.nome,
conta_corrente.numero,
conta_corrente.digito,
cliente.nome
FROM banco
JOIN agencia ON agencia.banco_numero = banco.numero
JOIN conta_corrente
-- ON conta_corrente.banco.numero = agencia.banco_numero
ON conta_corrente.banco_numero = agencia.numero
AND conta_corrente.agencia_numero = agencia.numero
JOIN cliente
ON cliente.numero = conta_corrente.cliente_numero
CTE(Common Table Expressions)
É uma forma auxiliar de organizar "statements", ou seja, blocos de códigos, para consultas muito grandes, gerando tabelas temporárias e criando relacionamentos entre elas. Dentro dos statements podem ser feitas operações de DML(SELECT, INSERT, UPDATE, DELETE).
Podemos criar estas tabelas temporárias com o statement WITH.
WITH [nome] AS (
SELECT (campos,)
FROM tabela_A
[WHERE]
), [nome2] AS (
SELECT (campos,)
FROM tabela_B
[WHERE]
)
SELECT [nome1].(campos,),[nome2].(campos,)
FROM [nome1]
JOIN [nome2] ....
Comandos utilizados em aula :
SELECT numero, nome FROM banco
SELECT banco_numero, numero, nome FROM agencia;
WITH tbl_tmp_banco AS (
SELECT numero, nome
FROM banco
)
SELECT numero, nome
FROM tbl_tmp_banco;
WITH params AS (
SELECT 213 AS banco_numero
), tbl_tmp_banco AS (
SELECT numero, nome
FROM banco
JOIN params ON params.banco_numero = banco.numero
)
SELECT numero, nome
FROM tbl_tmp_banco;
SELECT banco.numero, banco.nome
FROM banco
JOIN (
SELECT 213 AS banco_numero
) params ON params.banco_numero = banco_numero;
WITH clientes_e_transacoes AS (
SELECT cliente.nome AS cliente_nome,
tipo_transacao.nome AS tipo_transacao_nome,
cliente_transacoes.valor AS tipo_transacao_valor
FROM cliente_transacoes
JOIN cliente ON cliente.numero = cliente_transacoes.cliente_numero
JOIN tipo_transacao ON tipo_transacao.id = cliente_transacoes.tipo_transacao_id
)
SELECT cliente_nome, tipo_transacao_nome, tipo_transacao_valor
FROM clientes_e_transacoes;
WITH params AS (
SELECT 213 AS banco_numero
), tbl_tmp_banco AS (
SELECT numero, nome
FROM banco
JOIN params ON params.banco_numero = banco.numero
)
SELECT numero, nome
FROM tbl_tmp_banco;
SELECT banco.numero, banco.nome
FROM banco
JOIN (
SELECT 213 AS banco_numero
) params ON params.banco_numero = banco_numero;
WITH clientes_e_transacoes AS (
SELECT cliente.nome AS cliente_nome,
tipo_transacao.nome AS tipo_transacao_nome,
cliente_transacoes.valor AS tipo_transacao_valor
FROM cliente_transacoes
JOIN cliente ON cliente.numero = cliente_transacoes.cliente_numero
JOIN tipo_transacao ON tipo_transacao.id = cliente_transacoes.tipo_transacao_id
JOIN banco ON banco.numero = cliente_transacoes.banco_numero AND banco.nome ILIKE '%Itau%'
)
SELECT cliente_nome, tipo_transacao_nome, tipo_transacao_valor
FROM clientes_e_transacoes;
Views
Como o próprio nome diz, Views são visões. São apelidos para uma ou mais Querys. As Views nos dá a liberdade de não termos que ficar repetindo uma Query de uma busca por exemplo, sempre que necessitemos destes dados. As Views aceitam comandos de DML(SELECT, INSERT, UPDATE e DELETE) e podem ter definido seus campos de saída.
Atenção : Os comandos de INSERT, UPDATE e DELETE só funcionaram se a VIEW tiver apenas uma tabela.
Criando uma VIEW:
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] [ RECURSIVE ] VIEW name [ ( column_name [, ...] ) ]
[ WITH ( view_option_name [= view_option_value] [, ... ] ) ]
AS query
[ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
*A VIEW "TEMPORARY" só existe durante a sessão do usuário que criou a VIEW
*Como boas práticas sempre devemos utilizar o parâmetro OR REPLACE
Exemplo:
CREATE OR REPLACE VIEW vw_bancos AS (
SELECT numero, nome, ativo
FROM banco
);
VIEW RECURSIVE
Basicamente uma VIEW Recursiva ira chamar ela mesma(JOIN), fazendo com que entre em um tipo de loop até que tenha trazido todos os registros.
- Obrigatório o uso do UNION ALL
- Obrigatório a declaração dos campos de saída da VIEW
CREATE OR REPLACE RECURSIVE VIEW (nome_da_view) (campos_da_view) AS (
SELECT base
UNION ALL
SELECT campos
FROM tabela_base
JOIN (nome_da_view)
);
Exemplos utilizado em aula :
CREATE TABLE IF NOT EXISTS funcionarios (
id SERIAL NOT NULL,
nome VARCHAR(50),
gerente INTEGER,
PRIMARY KEY (id),
FOREIGN KEY (gerente) REFERENCES funcionarios (id)
);
INSERT INTO funcionarios (nome, gerente) VALUES ('Ancelmo',null);
INSERT INTO funcionarios (nome, gerente) VALUES ('Beatriz',1);
INSERT INTO funcionarios (nome, gerente) VALUES ('Magno',1);
INSERT INTO funcionarios (nome, gerente) VALUES ('Cremilda',2);
INSERT INTO funcionarios (nome, gerente) VALUES ('Wagner',4);
CREATE OR REPLACE RECURSIVE VIEW vw_funcionarios (id, gerente, funcionario) AS (
SELECT id, gerente, nome
FROM funcionarios
WHERE gerente IS NULL
UNION ALL
SELECT funcionarios.id, funcionarios.gerente, funcionarios.nome
FROM funcionarios
JOIN vw_funcionarios ON vw_funcionarios.id = funcionarios.gerente
);
SELECT id, gerente, funcionario
FROM vw_funcionarios
CREATE OR REPLACE RECURSIVE VIEW vw_funcionarios (id, gerente, funcionario) AS (
SELECT id, CAST(" AS VARCHAR) AS gerente, nome
FROM funcionarios
WHERE gerente IS NULL
UNION ALL
SELECT funcionarios.id, funcionarios.gerente, funcionarios.nome
FROM funcionarios
JOIN vw_funcionarios ON vw_funcionarios.id = funcionarios.gerente
JOIN funcionarios gerentes ON gerentes.id = vw_funcionarios.id
);
SELECT id, gerente, funcionario
FROM vw_funcionarios
WITH OPTIONS
- WITH LOCAL CHECK OPTION
- Significa que estou validando as opções da VIEW presente
CREATE OR REPLACE VIEW vw_bancos AS (
SELECT numero, nome, ativo
FROM banco
WHERE ativo IS TRUE
);
CREATE OR REPLACE VIEW vw_bancos_maiores_que_100 AS (
SELECT numero, nome, ativo
FROM vw_banco
WHERE numero > 100
) WITH LOCAL CHECK OPTION;
*Este comando ira retornar um erro pois o campo numero é menor que 100
INSERT INTO vw_bancos_maiores_100 (numero, nome, ativo) VALUES (99, 'Banco DIO', FALSE)
*Este comando ira passar pois o campo numero é maior que 100
INSERT INTO vw_bancos_maiores_100 (numero, nome, ativo) VALUES (200, 'Banco DIO', FALSE))
-- OK
WITH CASCADE CHECK OPTION
- Significa que estou validando as opções da VIEW atual e das VIEWS que utilizarem esta VIEW como referência.
CREATE OR REPLACE VIEW vw_bancos AS (
SELECT numero, nome, ativo
FROM banco
WHERE ativo IS TRUE
);
CREATE OR REPLACE VIEW vw_bancos_maiores_que_100 AS (
SELECT numero, nome, ativo
FROM vw_banco
WHERE numero > 100
) WITH CASCADED CHECK OPTION;
*Este comando ira retornar um erro pois o campo numero é menor que 100 e o ativo é FALSE
INSERT INTO vw_bancos_maiores_100 (numero, nome, ativo) VALUES (99, 'Banco DIO', FALSE)
*Este comando ira retornar um erro pois o campo ativo é FALSE
INSERT INTO vw_bancos_maiores_100 (numero, nome, ativo) VALUES (200, 'Banco DIO', FALSE))
-- ERRO
Comandos utilizados na aula
SELECT numero, nome, ativo
FROM banco;
CREATE OR REPLACE VIEW vw_bancos AS (
SELECT numero, nome, ativo
FROM banco
);
SELECT numero, nome, ativo
FROM vw_bancos;
CREATE OR REPLACE VIEW vw_bancos_2 (banco_numero, banco_nome, banco_ativo) AS (
SELECT numero, nome, ativo
FROM banco
);
SELECT banco_numero, banco_nome, banco_ativo
FROM vw_bancos_2
INSERT INTO vw_bancos_2 (banco_numero, banco_nome, banco_ativo)
VALUES (51, 'Banco Boa Idéia', TRUE);
SELECT banco_numero, banco_nome, banco_ativo FROM vw_bancos_2 WHERE banco_numero = 51;
SELECT numero, nome, ativo FROM banco WHERE numero = 51;
UPDATE vw_bancos_2 SET banco_ativo = FALSE WHERE banco_numero = 51;
SELECT banco_numero, banco_nome, banco_ativo FROM vw_bancos_2 WHERE banco_numero = 51;
SELECT numero, nome, ativo FROM banco WHERE numero = 51;
DELETE FROM vw_bancos_2 WHERE banco_numero = 51;
SELECT banco_numero, banco_nome, banco_ativo FROM vw_bancos_2 WHERE banco_numero = 51;
SELECT numero, nome, ativo FROM banco WHERE numero = 51;
CREATE OR REPLACE TEMPORARY VIEW vw_agencia AS (
SELECT nome FROM agencia
);
SELECT nome FROM vw_agencia;
CREATE OR REPLACE VIEW vw_bancos_ativos AS (
SELECT numero, nome, ativo
FROM banco
WHERE ativo IS TRUE
) WITH LOCAL CHECK OPTION;
INSERT INTO vw_bancos_ativos (numero, nome, ativo) VALUES (51, 'Banco Boa Idéia', FALSE);
-- ERRO
CREATE OR REPLACE VIEW vw_bancos_com_a AS (
SELECT numero, nome, ativo
FROM vw_bancos_ativos
WHERE nome ILIKE 'a%'
) WITH LOCAL CHECK OPTION;
SELECT numero, nome, ativo FROM vw_bancos_com_a;
INSERT INTO vw_bancos_com_a (numero, nome, ativo) VALUES (333,'Beta Omega', TRUE);
-- ERRO
INSERT INTO vw_bancos_com_a (numero, nome, ativo) VALUES (333,'Alfa Omega', TRUE);
INSERT INTO vw_bancos_com_a (numero, nome, ativo) VALUES (331,'Alfa Gama', FALSE);
-- ERRO
CREATE OR REPLACE VIEW vw_bancos_com_a AS (
SELECT numero, nome, ativo
FROM vw_bancos_ativos
WHERE nome ILIKE 'a%'
)WITH CASCADED CHECK OPTION;
INSERT INTO vw_bancos_com_a (numero, nome, ativo) VALUES (331,'Alfa Gama Beta', FALSE);
-- ERRO
Transações(Transactions)
É um conceito fundamental de todos os sistemas de bancos de dados onde múltiplas etapas/códigos são reunidos em apenas 1 transação, onde o resultado precisa ser tudo ou nada.
O escopo tradicional de declaração de uma transação começa com um BEGIN e termina com um COMMIT mas geralmente também pode possuir as clausulas ROLLBACK e SAVEPOINT.
BEGIN demarca o início do bloco de código.
COMMIT demarca o final onde o código é executado dentro do banco de dados.
SAVEPOINT salva um ponto específico dentro do código.
ROLLBACK volta para um ponto salvo anteriormente.
Exemplos:
BEGIN;
UPDATE conta SET valor = - 100.00
WHERE nome = 'Alice';
UPDATE conta SET valor = + 100.00
WHERE nome = 'Bob';
COMMIT;
BEGIN;
UPDATE conta SET valor = valor - 100.00
WHERE nome = 'Alice';
SAVEPOINT my_savepoint;
UPDATE conta SET valor = valor + 100.00
WHERE nome = 'Bob';
-- oops --- não é para o Bob, é para o Wally!!!
ROLLBACK TO my_savepoint;
UPDATE conta SET valor = valor + 100.00
WHERE nome = 'Wally';
COMMIT;
Comandos utilizados na aula:
SELECT numero, nome, ativo FROM banco ORDER BY numero ASC;
UPDATE banco SET ativo = false WHERE numero = 0;
SELECT numero, nome, ativo FROM banco ORDER BY numero ASC;
BEGIN;
UPDATE banco SET ativo = true WHERE numero = 0;
SELECT numero, nome, ativo FROM banco WHERE numero = 0;
ROLLBACK;
SELECT numero, nome, ativo FROM banco ORDER BY numero ASC;
BEGIN;
UPDATE banco SET ativo = true WHERE numero = 0;
COMMIT;
SELECT numero, nome, ativo FROM banco ORDER BY numero ASC;
SELECT id, gerente, nome
FROM funcionarios;
BEGIN;
UPDATE funcionarios SET gerente = 2 WHERE id = 3;
SAVEPOINT if_func;
UPDATE funcionarios SET gerente = null;
ROLLBACK TO if_func;
UPDATE funcionarios SET gerente = 3 WHERE id = 5;
COMMIT;
SELECT id, gerente, nome
FROM funcionarios;
Funções
São conjunto de códigos que são executados dentro de uma transação com a finalidade de facilitar a programação e obter o reaproveitamento/reutilização de códigos.
Existem 4 tipos de funções:
- query language functions (funções escritas em SQL).
- procedural language functions (funções escritas em, por exemplo PL/pqSQL ou PL/py).
- Internal functions
- C-language functions
O foco das aulas foi em USER DEFINED FUNCTIONS que são funções criadas pelo usuário.
Estas funções aceitam ser escritas em linguagens como : SQL(Funções escritas em SQL não aceitam transações), PL/PGSQL, PL/PY, PL/PHP, PL/RUBY, PL/JAVA, PL/LUA, entre outras.
Escopo de uma função:
CREATE [ OR REPLACE ] FUNCTION
name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
[ RETURNS rettype
| RETURNS TABLE ( column_name column_type [, ...] ) ]
{ LANGUAGE lang_name
| TRANSFORM { FOR TYPE type_name } [, ... ]
| WINDOW
| IMMUTABLE | STABLE | VOLATILE | [ NOT ] LEAKPROOF
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| PARALLEL { UNSAFE | RESTRICTED | SAFE }
| COST execution_cost
| ROWS result_rows
| SUPPORT support_function
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
*Sempre apelando para boas práticas, criar a função com "CREATE OR REPLACE"
RETURNS
Uma função pode retornar diversos tipos, tais como : INTEGER, CHAR / VARCHAR, BOOLEAN, ROW, TABLE, JSON.
Comportamento
- IMMUTABLE
- Não pode alterar o banco de dados.
- Funções que garantem o mesmo resultado para os mesmos argumentos/parâmetros da função. Evitar a utilização de selects, pois tabelas podem, sofrer alterações , tornando a função mutável e causando erros.
- STABLE
- Não pode alterar o banco de dados
- Funções que garantem o mesmo resultado para os mesmos argumentos/parâmetros da função. Trabalha melhor com tipos de current_timestamp e outros tipos variáveis. Podem conter selects.
- VOLATILLE
- comportamento padrão. Aceita todos os cenários.
Segurança e Boas Práticas
- CALLED ON NULL INPUT
- Padrão. Se qualquer um dos parâmetros/argumentos for NULL, a função será executada.
- RETURNS NULL ON NULL INPUT
- Se qualquer um dos parâmetros/argumentos for NULL, a função retornará NULL
- SECURITY INVOKER
- Padrão. A função é executada com as permissões de quem executa
- SECURITY DEFINER
- A função é executada com as permissões de quem criou a função.
Funções utilizadas em aula:
CREATE OR REPLACE FUNCTION banco_manage(p_numero INTEGER,p_nome VARCHAR(50),p_ativo BOOLEAN)
RETURNS TABLE (banco_numero INTEGER, banco_nome VARCHAR(50), banco_ativo BOOLEAN)
LANGUAGE PLPGSQL
SECURITY DEFINER
RETURNS NULL ON NULL INPUT
AS $$
BEGIN
-- O COMANDO ABAIXO VAI REALIZAR O INSERT OU O UPDATE DO BANCO
-- O COMANDO ON CONFLICT PPODE SER USADO PARA FAZER NADA (DO NOTHING)
-- OU PARA REALIZAR UM UPDATE NO NOSSO CASO.
INSERT INTO banco (numero, nome, ativo)
VALUES (p_numero, p_nome, p_ativo)
ON CONFLICT (numero) DO UPDATE SET nome = p_nome, ativo = p_ativo;
-- DEVEMOS RETORNAR UMA TABELA
-- O RETURN NESTE CASO DEVE SER UMA QUERY
RETURN QUERY
SELECT numero, nome, ativo
FROM banco
WHERE numero = p_numero;
END; $$;
CREATE OR REPLACE FUNCTION agencia_manage(p_banco_numero INTEGER, p_numero INTEGER, p_nome VARCHAR(80), p_ativo BOOLEAN)
RETURNS TABLE (banco_nome VARCHAR, agencia_numero INTEGER, agencia_nome VARCHAR, agencia_ativo BOOLEAN)
LANGUAGE PLPGSQL
SECURITY DEFINER
RETURNS NULL ON NULL INPUT
AS $$
DECLARE variavel_banco_numero INTEGER;
BEGIN
-- AQUI NÓS VAMOS VALIDAR A EXISTÊNCIA DO BANCO
-- E PRINCIPALMENTE SE ELE ESTÁ ATIVO
SELECT INTO variavel_banco_numero numero
FROM vw_bancos
WHERE numero = p_banco_numero
AND ativo IS TRUE;
-- SE OBTIVERMOS O RETORNO DO COMANDO ACIMA
-- ENTÃO O BANCO EXISTE E ESTÁ ATIVO
-- E PODEMOS PROSSEGUIR COM O INSERT DA AGÊNCIA
IF variavel_banco_numero IS NOT NULL THEN
-- O COMANDO ABAIXO VAI REALIZAR O INSERT OU O UPDATE DO BANCO
-- O COMANDO ON CONFLICT PPODE SER USADO PARA FAZER NADA (DO NOTHING)
-- OU PARA REALIZAR UM UPDATE NO NOSSO CASO.
-- !!! REPAREM QUE O UPDATE SÓ SERÁ REALIZADO NOS CAMPOS NOME E ATIVO DA AGENCIA !!!
-- !!! DESAFIO : QUE TAL MELHORAR ESSE CÓDIGO PARA SER POSSÍVEL A TROCA DE BANCO DAS AGÊNCIAS ???
INSERT INTO AGENCIA (banco_numero, numero, nome, ativo)
VALUES (p_banco_numero, p_numero, p_nome, p_ativo)
ON CONFLICT (banco_numero, numero) DO UPDATE SET
nome = p_nome,
ativo = p_ativo;
END IF;
-- DEVEMOS RETORNAR UMA TABELA
-- O RETURN NESTE CASO DEVE SER UMA QUERY
RETURN QUERY
SELECT banco.nome AS banco_nome,
agencia.numero AS agencia_numero,
agencia.nome AS agencia_nome,
agencia.ativo AS agencia_ativo
FROM agencia
JOIN banco ON banco.numero = agencia.numero
WHERE agencia.banco_numero = p_banco_numero
AND agencia.numero = p_numero;
END; $$;
CREATE OR REPLACE FUNCTION cliente_manage(p_numero INTEGER, p_nome VARCHAR(120), p_email VARCHAR(250), p_ativo BOOLEAN)
RETURNS BOOLEAN
LANGUAGE PLPGSQL
SECURITY DEFINER
CALLED ON NULL INPUT
AS $$
BEGIN
-- VAMOS VALIDAR SOMENTE OS PARÂMETROS MAIS IMPORTANTES
IF p_numero IS NULL OR p_nome IS NULL THEN
RETURN FALSE;
END IF;
-- FAREMOS O INSERT COM TRATAMENTO DE VALORES NULOS
INSERT INTO cliente (numero, nome, email, ativo)
VALUES (p_numero, p_nome, COALESCE(p_email,CONCAT(p_nome,'@sem_email')), COALESCE(p_ativo,TRUE))
ON CONFLICT (numero) DO UPDATE SET nome = p_nome, email = CONCAT(p_nome,'@sem_email'), ativo = COALESCE(p_ativo,TRUE);
RETURN TRUE;
END; $$;











