

Python no meu filme: análise exploratória de dados. Aplique no seu entretenimento, saiba como?
- #Data
- #Python
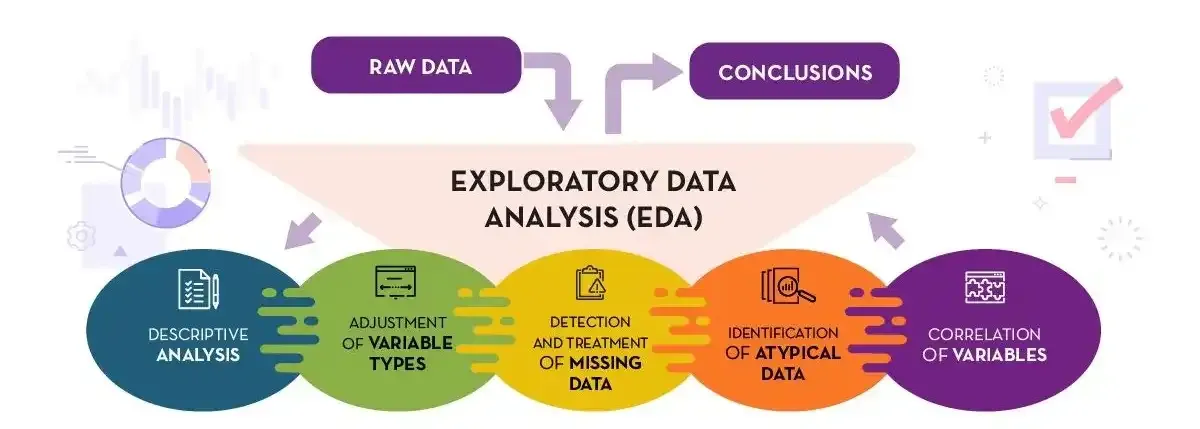
Análise Exploratória de Dados (EDA)
Como funciona
- EDA é um processo iterativo que envolve gerar perguntas sobre os dados, visualizá-los, transformá-los e modelá-los
- EDA usa uma combinação de ferramentas estatísticas e métodos de descoberta de dados
- EDA é mais como um trabalho de detetive, sem uma ideia estabelecida sobre o que os dados podem revelar
Vantagens
- EDA ajuda a identificar padrões, anomalias, relações, ou insights sem preconcepções
- EDA ajuda a determinar como manipular fontes de dados para obter as respostas desejadas
- EDA ajuda a identificar problemas de qualidade de dados, como valores ausentes ou erros
- EDA ajuda a desenvolver modelos preditivos precisos
História
- EDA foi desenvolvida por John Tukey, um matemático americano, na década de 1970
- Tukey acreditava que muito ênfase era dada na estatística à testagem de hipóteses estatísticas, e que mais ênfase deveria ser dada ao uso de dados para sugerir hipóteses a serem testadas
Aplicando a técnica (EDA) em Filmes dos Anos 1990 com Python
Introdução
A Análise Exploratória de Dados (EDA) é um processo essencial para compreender um conjunto de dados antes de aplicar modelagens preditivas ou realizar inferências estatísticas. Neste artigo, exploraremos dados abertos de filmes dos anos 1990, identificando padrões, valores ausentes, outliers e relações entre variáveis.
1. Coleta e Limpeza dos Dados
O primeiro passo da EDA é garantir que os dados estejam organizados e prontos para análise. Para isso, devemos:
- Identificar e tratar valores ausentes: Em campos como "orçamento", "bilheteria" ou "nota do IMDb", podem existir lacunas.
- Remover inconsistências: Exemplo: orçamentos negativos ou bilheterias superiores a valores realistas.
- Padronizar variáveis: Converter datas para um formato comum e padronizar gêneros de filmes.
Exemplo prático em Python:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from kagglehub import KaggleDatasetAdapter
# Carregar dataset do Kaggle
file_path = "tmdb-movies.csv"
df = KaggleDatasetAdapter.PANDAS.load_dataset("asaniczka/tmdb-movies-dataset-2023-930k-movies", file_path) **
# Filtrar filmes dos anos 1990
df["release_year"] = pd.to_datetime(df["release_date"], errors='coerce').dt.year
df_90s = df[(df["release_year"] >= 1990) & (df["release_year"] < 2000)]
# Verificar valores ausentes
df_90s.isnull().sum()
# Remover valores ausentes
df_90s = df_90s.dropna(subset=["budget", "revenue", "vote_average"])
**Observe que a fonte de dados de encontra dos exemplos está na instrução da variável definida na seção # Carregar dataset do Kaggle
2. Estatísticas Descritivas e Distribuição dos Dados
Para entender melhor os dados, algumas estatísticas são extraídas:
- Média, mediana e desvio padrão de orçamentos e bilheterias.
- Distribuição de notas dos filmes no IMDb e Rotten Tomatoes.
- Frequência dos gêneros mais populares.
Exemplo em Python de estatística descritiva:
# Estatísticas descritivas
df_90s[['budget', 'revenue', 'vote_average']].describe()
# Histograma de notas dos filmes
sns.histplot(df_90s["vote_average"], bins=20, kde=True)
plt.title("Distribuição de notas dos filmes")
plt.show()
3. Identificação de Outliers
Outliers podem distorcer a análise, sendo importante identificá-los:
Filmes com bilheteria excessivamente alta ou baixa.
Orçamentos extremamente elevados comparados à média.
Duração de filmes muito acima ou abaixo do padrão.
A análise de outliers pode ser feita por meio de boxplots e testes estatísticos como o Z-Score.
Exemplo prático em Python:
# Boxplot de orçamento
sns.boxplot(x=df_90s["budget"])
plt.title("Distribuição de Orçamentos")
plt.show()
4. Correlações Entre Variáveis
Uma parte fundamental da EDA é entender as relações entre variáveis:
- Correlação entre orçamento e bilheteria: Filmes com maior investimento tendem a gerar mais receita?
- Relação entre nota da crítica e sucesso comercial.
- Impacto do gênero na bilheteria.
A matriz de correlação e gráficos de dispersão são úteis para essa etapa.
Exemplo prático em Python:
# Matriz de correlação
sns.heatmap(df_90s[['budget', 'revenue', 'vote_average']].corr(), annot=True, cmap='coolwarm')
plt.title("Matriz de Correlação")
plt.show()
5. Tendências ao Longo da Década
Com base nos dados, podemos analisar padrões temporais:
- Evolução do orçamento médio dos filmes.
- Mudanças na preferência de gêneros ao longo dos anos.
- Tendência de duração dos filmes.
Gráficos de linhas ajudam a visualizar essas tendências.
Exemplo prático em Python:
# Evolução do orçamento médio ao longo da década
df_90s.groupby("release_year")["budget"].mean().plot(kind='line', marker='o')
plt.title("Orçamento Médio por Ano")
plt.xlabel("Ano")
plt.ylabel("Orçamento Médio")
plt.show()
Conclusão
A Análise exploratória de dados (Exploratory data analysis) ou EDA é um processo essencial para extrair insights valiosos de um conjunto de dados. No caso dos filmes dos anos 1990, conseguimos entender padrões de bilheteria, impacto do orçamento e tendências ao longo da década. Esses insights podem ser usados tanto para previsão de sucessos futuros quanto para entender melhor a história do cinema. O artigo pode ser adaptado pelo leitor com a fonte de dados abertos da preferência. No artigo utilizo a fonte do Kaglle: https://www.kaggle.com/datasets/asaniczka/tmdb-movies-dataset-2023-930k-movies?select=TMDB_movie_dataset_v11.csv
Referências:
- Guia completo: Análise exploratória de dados com Python: https://medium.com/@renata-biaggi/guia-completo-análise-exploratória-de-dados-com-python-2964fa2940f4
- A Data Scientist’s Essential Guide to Exploratory Data Analysis: https://towardsdatascience.com/a-data-scientists-essential-guide-to-exploratory-data-analysis-25637eee0cf6/?source=post_page-----24028d7013b3---------------------------------------
- Análise Exploratória de Dados com Python: https://medium.com/@aasouzaconsult/python-para-análise-de-dados-24028d7013b3






