


Noções básicas sobre SQL
- #SQL
Structured Query Language, ou SQL (pronuncia-se see-quel), é a linguagem usada para consultar e manipular dados e definir estruturas em bancos de dados. Inicialmente desenvolvido na IBM no início da década de 1970, o SQL tornou-se um padrão ANSI e ISO em 1986.
SQL é uma linguagem poderosa, mas simples, e pode fazer muitas coisas, como executar consultas, recuperar, inserir, atualizar e excluir dados, criar bancos de dados e tabelas e muito mais.
Esses tipos de atividades podem ser agrupados em diferentes subdivisões do SQL: DDL (Data Definition Language), DML (Data Manipulation Language) e DCL (Data Control Language):
- Use comandos DDL para especificar o esquema do banco de dados:
- CREATE: Isso é usado para criar um novo banco de dados ou objetos em um banco de dados.
- ALTER: Isso é usado para alterar um banco de dados ou objetos em um banco de dados.
- DROP: Isso é usado para excluir um banco de dados ou objetos em um banco de dados.
- TRUNCATE: Isso é usado para remover todos os dados de uma tabela instantaneamente.
- Use comandos DML para consultar e modificar dados:
- SELECT: Isso é usado para recuperar dados de um banco de dados.
- INSERT: Isso é usado para inserir dados em um banco de dados.
- UPDATE: Isso é usado para atualizar dados em um banco de dados.
- DELETE: Isso é usado para remover dados de um banco de dados.
- Use comandos DCL para controlar permissões e traduções:
- GRANT: Isso é usado para dar acesso a um usuário.
- REVOKE: Isso é usado para tirar o acesso de um usuário.
- COMMIT: Isso é usado para salvar alterações em uma transação.
- ROLLBACK: Isso é usado para remover as alterações salvas em uma transação.
Elementos do SQL
A linguagem SQL é composta por vários elementos que serão explicados com mais profundidade nos próximos capítulos. Esses elementos incluem o seguinte:
- Consultas que recuperam dados com base em critérios específicos.
- Cláusulas que são componentes de instruções ou consultas.
- Predicados que são condições lógicas que avaliam como verdadeiro ou falso. Isso ajuda você a restringir os resultados de suas consultas.
- Expressões que produzem valores escalares ou tabelas de colunas e linhas. As expressões fazem parte dos predicados.
- As instruções que são consultas são executadas em um banco de dados, composto de cláusulas e, opcionalmente, expressões e predicados.
- Espaço em branco que geralmente é ignorado em instruções e consultas SQL, facilitando a formatação para facilitar a leitura, pois você não precisa se preocupar tanto com o espaçamento específico para que o SQL seja executado corretamente.
O diagrama a seguir mostra os componentes de uma instrução SQL, que também é chamada de consulta SQL:

No diagrama anterior, você pode ver os diferentes elementos de uma instrução SQL. Cada linha na instrução anterior é considerada uma cláusula. As cláusulas usam palavras-chave SQL. Palavras-chave são palavras reservadas que têm significado especial na linguagem SQL — , e são apenas algumas das palavras-chave usadas. Mais informações sobre palavras-chave são fornecidas no Capítulo 4, Projetando e criando um banco de dados. O diagrama anterior também mostra uma expressão e um predicado. Um predicado ajuda a restringir os resultados da consulta. A expressão é uma parte de um predicado que define o valor. O diagrama também ajuda a ilustrar o uso de espaço em branco. Você pode escrever toda a sua consulta em uma linha, mas é muito mais fácil de ler quando você adiciona retornos de carro e espaços. Os detalhes dos diferentes elementos das consultas serão abordados mais detalhadamente nos próximos capítulos deste livro. SELECTFROMWHERE
Noções básicas sobre bancos de dados
Um banco de dados é uma coleção de dados. Você armazena bancos de dados em um sistema de gerenciamento de banco de dados relacional (RDMS). O RDMS é a base para sistemas de banco de dados modernos como MySQL, SQL Server, Oracle, PostgreSQL, entre outros. Estes serão abordados em mais detalhes mais adiante neste capítulo.
Tabelas
Em um RDMS, objetos chamados tabelas armazenam dados. As tabelas são uma coleção de dados relacionados armazenados em colunas e linhas. A captura de tela a seguir é uma seção transversal de uma tabela que contém dados sobre as aparições de jogadores de beisebol em jogos all-star:
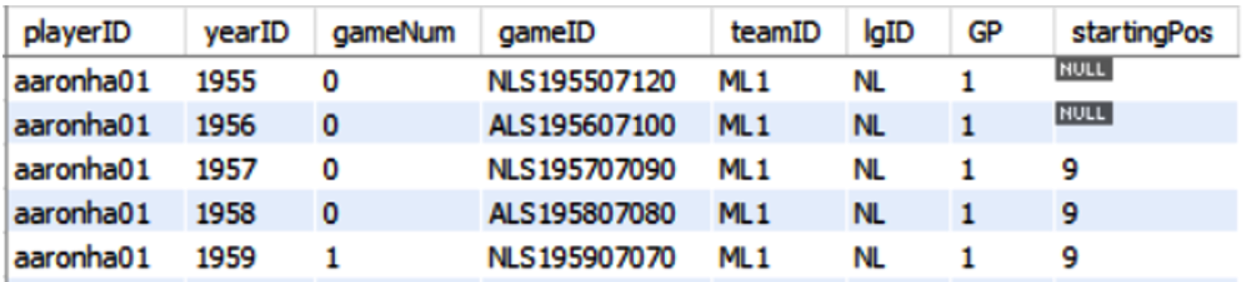
Um valor NULL em uma tabela é um valor que parece estar em branco. Ele não representa uma cadeia de caracteres de espaços em branco, zero ou uma cadeia de caracteres de comprimento zero: é um valor ausente ou desconhecido.
Os dados foram obtidos de http://www.seanlahman.com/baseball-archive/statistics/ com uma licença CC BY-SA 3.0.
Campos
Um campo é uma interseção de uma linha e uma coluna. Esse campo pode ser qualquer tipo de dado, incluindo um , ou um campo (usando nosso exemplo). Cada seta vermelha na captura de tela a seguir aponta para um valor em uma coluna que é considerado um campo:yearIDteamIDplayerID

Registros ou linhas
Uma linha contém valores em uma divisão horizontal de dados. Neste caso de exemplo, é uma linha ou registro de uma tabela:

Colunas
Uma coluna contém valores em uma divisão vertical de dados. Neste caso de exemplo, é a coluna de uma tabela:gameID

Para garantir que os dados em suas tabelas sejam consistentes e precisos, você precisará entender a integridade dos dados. Você aprenderá sobre integridade de dados na próxima seção.
Noções básicas sobre a integridade dos dados
A integridade dos dados refere-se à consistência e precisão dos dados. Normalmente, ela é imposta pelos procedimentos e diretrizes na fase de design do banco de dados. No RDMS, as chaves impõem a integridade dos dados. Uma chave é definida pelo usuário e força os valores em uma tabela a estarem em conformidade com um padrão especificado. Esse padrão permitirá que apenas determinados tipos de valores estejam no banco de dados.
Tipos de integridade
A integridade dos dados refere-se à consistência e precisão dos dados e das relações de tabela.
Integridade da entidade
Para garantir que cada linha em uma tabela seja identificavelmente exclusiva, use a integridade da entidade. Isso é feito com alguns tipos diferentes de chaves ou restrições, incluindo restrições de chave exclusiva, não nula e primária.
Restrições exclusivas
Para garantir que todos os valores em uma coluna ou colunas sejam diferentes entre si, use uma restrição exclusiva.Esse tipo de chave pode ser aplicado a qualquer tipo de dados e é usado para evitar dados duplicados. Você pode aplicar uma restrição exclusiva a várias colunas para que ela crie um valor exclusivo nessas várias colunas. Ele pode conter valores nulos.
Se você criar uma restrição exclusiva em uma coluna, ela forçará a tabela a ter valores exclusivos nessa coluna específica. Se eles não forem exclusivos, a linha não poderá ser inserida ou atualizada.
Na captura de tela a seguir, a restrição é exclusiva. Todos os outros campos podem ter informações duplicadas, desde que a restrição exclusiva não seja violada:parkkey parkkey

Se você criar uma restrição exclusiva em uma combinação de colunas em uma tabela, ela forçará a tabela a ter valores exclusivos na combinação dessas colunas na restrição exclusiva. Se eles não forem exclusivos, a linha não poderá ser inserida ou atualizada.
A captura de tela a seguir mostra um exemplo de uma restrição composta e exclusiva. Nesse caso, , e precisaria ser exclusivo para que a linha fosse aceitável:playerIDyearIDteamID

Restrições não nulas
Para garantir que todos os valores em uma coluna não sejam nulos, use uma restrição não nula. Esse tipo de chave pode ser aplicado a qualquer tipo de dados e é usado para evitar dados ausentes. Se você criar uma restrição não nula em uma coluna, ela forçará a tabela a ter valores nessa coluna específica. Se os valores forem nulos, a linha não será inserida ou atualizada.
Na captura de tela a seguir, você pode ver que a restrição está definida como não nula. A restrição permitiria nulos, já que nem todas as pessoas têm um ano de morte:birthYear deathYear

A chave primária
A chave primária é usada para garantir que todos os valores em uma coluna não sejam nulos e exclusivos. Essa chave combina as propriedades de restrição exclusivas e não nulas em uma chave. Esse tipo de chave pode ser aplicado a qualquer tipo de dados e é usado para evitar dados ausentes e duplicados. Você só pode ter uma chave primária por tabela.
Se você criar uma chave primária em uma tabela, ela forçará a tabela a ter valores exclusivos, não nulos, nessa coluna específica. Se os valores não estiverem em conformidade, a linha não poderá ser inserida ou atualizada. Você também pode criar uma chave primária em várias colunas. Isso é considerado uma chave composta. Nesse caso, a chave composta teria que ser exclusiva para cada linha, caso contrário, a linha não poderia ser inserida ou atualizada.
Na captura de tela a seguir, a restrição seria a chave primária porque é exclusiva e não nula para cada linha da tabela:playerID

Na captura de tela a seguir, as restrições , e podem ser a chave primária composta porque a combinação dessas três colunas é exclusiva e não nula para cada linha da tabela: playerIDyearIDteamID

Integridade referencial
A integridade referencial refere-se à consistência e precisão entre tabelas que podem ser interligadas. Ao ter uma chave primária na tabela pai e uma chave estrangeira na tabela filho, você alcança a integridade referencial. Uma chave estrangeira na tabela filho cria um link entre uma ou mais colunas na tabela filho e a chave primária na tabela pai. Quando uma chave estrangeira está presente, ela deve fazer referência a uma chave primária válida e existente na tabela pai. Dessa forma, os dados em ambas as tabelas podem manter uma relação adequada. Você aprenderá mais sobre isso no exemplo a seguir.
Se você não configurar a integridade referencial, acabará com registros órfãos. Por exemplo, digamos que você exclua um jogador da primeira tabela aqui:

Agora digamos que você não excluiu o registro correspondente na segunda tabela aqui. Nesse caso, os registros da segunda tabela ficariam órfãos:

Se houvesse uma restrição de chave estrangeira na coluna, o jogador não poderia ser excluído da tabela pai sem primeiro excluir as linhas salariais correspondentes na tabela salarial. Ao ter uma restrição de chave estrangeira, também impediremos que os usuários adicionem linhas à tabela filho sem uma linha pai correspondente ou alterem valores em uma tabela pai que resultaria em registros de tabela filho órfãos.salary
Você não receberá um erro se houver dados incompletos quando você não tiver restrições de integridade referencial. É basicamente como se seus registros fossem perdidos no banco de dados, já que eles podem nunca aparecer em relatórios ou resultados de consulta. Isso pode causar todos os tipos de problemas, como resultados estranhos, pedidos perdidos e potencialmente situações de vida ou morte em que (por exemplo) os pacientes não recebem tratamentos adequados.
Ao criar uma restrição de chave estrangeira, a chave estrangeira must faz referência a uma coluna em outra tabela que é a chave primária. Pode ser qualquer tipo de dados e aceitar valores duplicados e nulos por padrão. A restrição de chave estrangeira pode manter três tipos de relações de tabela (abordadas com mais detalhes no Capítulo 7, Consultando várias tabelas):
- Um-para-um: esse tipo de relação ocorre quando uma tabela tem apenas uma linha correspondente em outra tabela. Um exemplo disso poderia ser uma tabela com funcionários e computadores. Cada funcionário tem um computador.
- Um-para-muitos: esse tipo de relação ocorre quando uma tabela tem nenhuma, uma ou muitas linhas correspondentes em outra tabela. Um exemplo disso poderia ser uma mesa com adultos e crianças. Uma linha de tabela adulta pode ter nenhuma, uma ou muitas linhas na tabela filha.
- Muitos para muitos: esse tipo de relação ocorre quando muitas linhas em uma tabela correspondem a muitas linhas em outra tabela. Um exemplo disso poderia ser o e tabelas. Os clientes podem comprar muitos produtos. customersproducts
Nas capturas de tela a seguir, a chave primária estaria na primeira tabela como . A segunda tabela teria uma referência de chave estrangeira na primeira tabela. Neste caso, haveria uma relação um-para-muitos entre a primeira e a segunda mesa, porque há um jogador na primeira tabela e nenhuma, uma ou muitas linhas correspondentes a esse jogador na segunda tabela.playerIDplayerID
Se você tivesse uma configuração de chave estrangeira na segunda tabela, não seria possível excluir o valor da primeira tabela, a menos que o excluísse na segunda tabela antes. Essa configuração de chave mantém a integridade referencial e garante que você não terá registros órfãos na segunda tabela:playerIDplayerID

Integridade do domínio
Para garantir que os valores de dados sigam regras definidas para formatação, intervalo e valor usando restrições de verificação e padrão, use a integridade do domínio.
A restrição de verificação é usada para garantir que todos os valores em uma coluna estejam dentro de um intervalo de valores. Esse tipo de chave pode ser aplicado a qualquer tipo de dados e é usado para garantir que os valores não sejam inválidos. Uma restrição de verificação é imposta com condições definidas pelo usuário e avaliada como verdadeira ou falsa. Você pode definir uma restrição de verificação em uma única coluna ou uma combinação de colunas em uma tabela.
Como null não é avaliado como false, ele pode ser inserido ou atualizado em um campo com uma restrição de verificação. Assim, como null é avaliado como desconhecido, ele pode ignorar uma restrição de verificação. Se você quiser que a coluna com uma restrição de verificação não permita null, você também precisará definir uma restrição não nula na coluna.
A captura de tela a seguir mostra um exemplo de uma tabela em que uma restrição de verificação faria sentido na coluna introduzida. Um jogador pode ser introduzido no hall da fama ou não. Nesse caso, você pode criar uma restrição de verificação que só permite ou nesse campo. Se o valor não for ou , a linha não poderá ser atualizada ou inserida:YNYN

A captura de tela a seguir mostra um exemplo de uma tabela em que uma restrição de verificação pode ser aplicada a várias colunas. Por exemplo, você não gostaria de estar um ano antes do , então você pode definir uma restrição de verificação que só permitirá que você adicione ou atualize uma ou que siga uma restrição de verificação como:deathYearbirthYearbirthYeardeathYearbirthYear < deathYear

Para garantir que todas as linhas em uma coluna tenham um valor, use uma restrição padrão. Esse tipo de chave pode ser aplicado a qualquer tipo de dados. Uma restrição padrão atribui um valor padrão a um campo. Isso é usado para evitar ter um valor nulo para um campo se um usuário não especificar um valor.
A captura de tela a seguir mostra um exemplo de uma tabela em que uma restrição padrão pode fazer sentido na coluna:ab

Um jogador pode estar em um jogo sem ter nenhum at-bats. Nesse caso, você pode criar uma restrição padrão que define a coluna como se o usuário não fornecer nenhum valor. ab0
Normalização do banco de dados
A normalização do banco de dados é o processo de colocar os dados brutos em tabelas usando regras para evitar dados redundantes, otimizar o desempenho do banco de dados e garantir a integridade dos dados.
Sem a normalização adequada, você não só pode ter redundância de dados, que usa espaço de armazenamento adicional, mas pode ser mais difícil atualizar e manter o banco de dados sem perda de dados.
A normalização requer formulários. Os formulários são conjuntos de regras a serem seguidas para normalizar seus dados em tabelas de banco de dados. Há três formas que discutiremos: a primeira forma normal, a segunda forma normal e a terceira forma normal. Cada um desses formulários tem um conjunto de regras para garantir que seu banco de dados esteja em conformidade com o formulário. Cada um dos formulários se baseia nos formulários anteriores.
A primeira forma normal
A primeira forma normal (1NF) é o primeiro nível de normalização do banco de dados. Você precisará concluir esta etapa antes de prosseguir para outros formulários de normalização de banco de dados. A principal razão para implementar o 1NF é eliminar grupos repetitivos. Isso garante que você possa usar instruções SQL simples para consultar os dados. Ele também garante que você não esteja duplicando dados, o que usa armazenamento adicional e tempo de computação. Esta etapa garantirá que você esteja fazendo o seguinte:
- Definindo dados, colunas e tipos de dados e colocando dados relacionados em colunas
- Eliminando grupos repetidos de dados:
- Isso significa que você não terá colunas repetidas, como , , , mas terá uma coluna chamada , e cada linha na tabela será um ano diferente. Year1Year2Year3Year
- Outro exemplo disso é não ter vários valores no mesmo campo, como , , , mas colocar cada ano em uma linha. 198519871989
- Isso significa que não há linhas duplicadas exatas. O exemplo a seguir a esta lista de marcadores explicará esse conceito com mais profundidade.
- Criando uma chave primária para cada tabela
No exemplo a seguir, você pode tornar a primeira coluna a chave primária na tabela de pessoas e a chave estrangeira na tabela de salários. Na tabela de salários, você pode criar uma nova chave primária ou criar uma chave composta que seja uma fusão de vários campos.
Para resumir o processo de levar os dados de desnormalizados para o terceiro normal, aqui está um diagrama das alterações que são feitas:

O diagrama anterior mostra como você passou de desnormalizado para 3NF. Seguindo as regras dos formulários normais, você pegou uma única tabela e a transformou em quatro tabelas. Para começar, você divide uma tabela desnormalizada em duas tabelas como parte do 1NF. O 1NF garantiu que você não tivesse dados duplicados e grupos repetidos. Isso resultou em uma tabela de jogadores e franquias. Em seguida, você divide as tabelas em três tabelas como parte do 2NF. A 2NF resolveu a questão de não dar a cada mesa um propósito específico, resultando em um jogador, franquia e mesa de rebatedores. Para a etapa final, você divide as tabelas em quatro tabelas como parte do 3NF. O 3NF garantiu que você não tivesse campos em uma tabela que não dependesse da chave primária, resultando em uma tabela de jogadores, franquias, rebatedores e equipes.
Ao passar de uma tabela desnormalizada para 3NF, você conseguiu várias coisas, incluindo garantir que não tenha dados duplicados, que tenha chaves vinculando dados entre si nas tabelas, que tenha uma única finalidade para cada tabela e que tenha minimizado os custos de armazenamento e computação para suas consultas.
Mesmo a adesão à terceira forma normal pode ser levada a extremos, portanto, embora a terceira forma normal seja desejável, nem sempre é necessária. Por exemplo, com códigos postais, você pode criar uma tabela apenas com CEPs, já que eles podem ser duplicados em uma tabela com os endereços dos usuários, mas isso pode prejudicar o desempenho em vez de ajudar o desempenho.
Tipos de RDMS
Um RDMS é um banco de dados que armazena dados em tabelas usando linhas e colunas. Os valores nas tabelas estão relacionados entre si, e as tabelas também podem estar relacionadas entre si, daí o termo relacional. Essa relação possibilita acessar dados em várias tabelas com uma única consulta.
Nesta seção, analisaremos os quatro principais sistemas de gerenciamento de banco de dados relacional. Os quatro primeiros são Oracle, MySQL, SQL Server e PostgreSQL.
De acordo com o DB-Engines Ranking, aqui estão as pontuações para os principais RDMSes no momento da escrita deste livro:

A captura de tela anterior pode ser encontrada em https://db-engines.com/en/ranking.
Oráculo
Oracle foi lançado pela primeira vez em 1979. Oracle foi o primeiro RDMS baseado em SQL disponível comercialmente. Ele tem uma versão gratuita, Oracle Database XE, que tem algumas limitações em comparação com suas versões licenciadas. O Oracle roda melhor no Linux, mas pode ser instalado no Windows. O Oracle é uma ótima opção para organizações que precisam de um RDMS e podem lidar com bancos de dados muito grandes e uma variedade de recursos.
As vantagens do Oracle são que ele oferece muitas funcionalidades para administradores de sistemas e bancos de dados, é rápido e estável, e tem muito suporte e documentação.
As desvantagens do Oracle são que o licenciamento é caro e pode exigir recursos significativos do administrador de banco de dados para mantê-lo após a instalação.
MySQL
MySQL é um banco de dados SQL gratuito e de código aberto que começou em 1995. Também possui licenciamento proprietário disponível, que inclui suporte e manutenção. A Sun Microsystems comprou o MySQL em 2008, que foi então adquirido pela Oracle em 2010. MySQL é comumente usado em conjunto com aplicações web PHP. O MySQL é uma ótima opção para organizações que precisam de um bom RDMS, mas têm um orçamento apertado.
As vantagens do MySQL são que ele está disponível gratuitamente, oferece muitas funcionalidades para administradores de sistema e banco de dados, é fácil de usar e implementar, e é rápido e estável.
As desvantagens do MySQL são que, embora o suporte esteja disponível, ele não é gratuito. Além disso, como está sob a Oracle, nem todos os recursos são gratuitos, incluindo opções pagas, como monitoramento corporativo, backup, alta disponibilidade, escalabilidade e segurança.
SQL Server
Lançado inicialmente em 1989, o SQL Server está disponível com uma licença comercial. Ele tem uma versão gratuita, SQL Server Express, com uma limitação de 10 GB por banco de dados, juntamente com outras limitações de recursos. O SQL Server geralmente é instalado no Windows, mas também pode ser instalado no Linux. O SQL Server é uma ótima opção para organizações que precisam de um bom RDMS e usam muitos outros produtos da Microsoft.
As vantagens do SQL Server são que eleoferece muitas funcionalidades, incluindo replicação, alta disponibilidade e particionamento muitobem com outros produtos da Microsoft, como .NET Framework e Visual Studio. Também é faste estável.
As desvantagens do SQL Server são que o licensing é caro, especialmente para a edição Enterprise, e n ot todos os recursos estão incluídos em todas as edições, como algumas opções de alta disponibilidade e particionamento.
PostgreSQL
A primeira versão do PostgreSQL foi em 1989. Isso indefinidamente e não impõe nenhum limite. O PostgreSQL geralmente é instalado em máquinas Linux e pode ser usado para armazenar dados estruturados e não estruturados. O PostgreSQL é uma ótima opção para organizações que precisam de um bom RDMS, já usam Linux e não querem gastar muito dinheiro com licenciamento.
As vantagens do PostgreSQL são que elepossui muitas funcionalidades, como alta disponibilidade e particionamento, éescalável e pode lidar com terabytes de dados, além de ser estávele estável.
As desvantagens do PostgreSQL são que a documentação pode ser mais difícil de encontrar e c onfiguração pode serconfusa. Ele também roda no Linux, e você precisa saber como executar comandos do Prompt de Comando.
Diferenças de SQL do RDMS
Embora haja um padrão ANSI/ISO, existem diferentes versões do SQL. Ainda assim, para ser compatível, todos eles suportam igualmente os comandos principais, então , , , , e todos teriam uma sintaxe que corresponde.SELECTWHEREINSERTUPDATEDELETE
Cada capítulo subsequente deste livro também observará diferenças na linguagem ou funcionalidade do SQL, onde há diferenças entre MySQL e SQL Server, PostgresSQL e Oracle.
Referencias :
Oracle:
MySQL:
SQL Server:
PostgreSQL:




