


Learn About The Architecture of Deep Neural Networks (DNN's)
- #Machine Learning
The Architecture of Deep Neural Networks (DNN's)

The Architect (Helmut Bakaitis) | Movie: Matrix Reloaded — 2003
Neural networks are commonly represented as directed graphs, where neurons are the vertices and synapses are the edges. The direction of the edges indicates the type of feeding, that is, how neurons receive input signals.
A typical neural network consists of a set of interconnected neurons, forming a larger system capable of storing knowledge acquired through presented examples and thus being able to make inferences on new datasets.
The power of neural networks stems from their massive and parallel structure, as well as their ability to learn from experience. This experience is transmitted through examples obtained from the real world, defined as a set of features comprised of input and output data.
When we present both the input and output data to the network, we are facing Supervised Learning, whereas if we present only the input data, we are facing Unsupervised Learning.
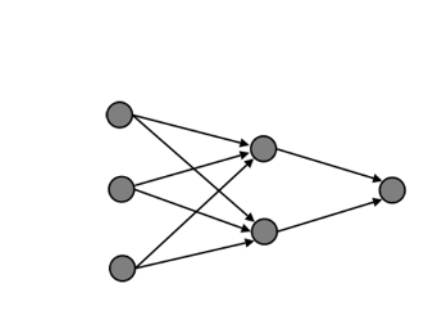
The vertices are the neurons. The edges are the synapses.
The knowledge obtained by the network through examples is stored in the form of connection weights, which will be adjusted to make correct decisions based on new inputs, i.e., new real-world situations unknown to the network.
The process of adjusting the synaptic weights is carried out by the learning algorithm, responsible for storing real-world knowledge obtained through examples in the network. There are several learning algorithms, among which Backpropagation is the most commonly used algorithm.
The architecture of a neural network refers to the arrangement of neurons in the network, i.e., how they are structured. The network’s architecture is directly linked to the type of learning algorithm used.
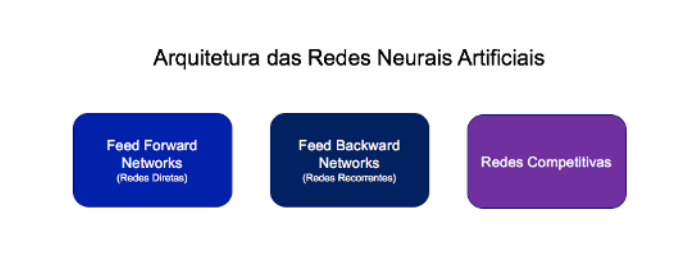
Title: Artificial Neural Networks Architecture | Left: FFNs (Direct Networks) |
Center: FBNs (Recurrent Networks) | Right: CN (Competitive Networks)
In general, you can identify three main classes of network architecture. Let’s look at each one:
1st) Feed Forward Networks (FFNs):
Some types of networks are structured in layers, where neurons are arranged in distinct and sequentially ordered sets called layers. In feedforward networks, the flow of information always goes from the input layer to the output layer.
Feed Forward Networks can be Single-Layer Networks or Multi-Layer Networks, with the only difference being the number of layers, but the concept of feed forward or direct feeding remains the same.
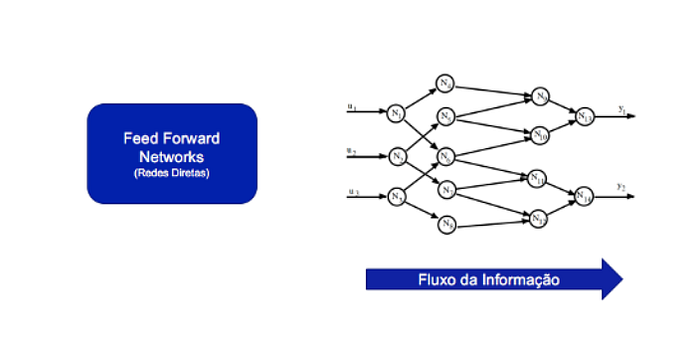
Left: FFNs (Direct Networks) | Right: Inside The Blue Arrow: “Information Flow”
Some important characteristics of a Feed Forward Network are:
- The neurons are arranged in layers, with the initial layer receiving the input signals while the final layer gets the outputs. The intermediate layers are called hidden layers.
- Each neuron in a layer is connected to all neurons in the next layer.
- There are no connections between neurons in the same layer.
2nd) Feed Backward Networks (Recurrent Networks):
In recurrent nets there is feedback, in which the output of a neuron is applied as input in the neuron itself and/or in other neurons of previous layers, that is, there is a cycle in the graph.
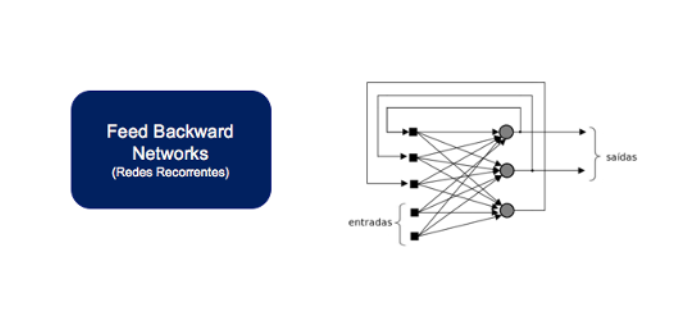
Left: FBNs (Recurrent Networks) | Right: On The 1st Curly Braces: “Inputs” |
On The 2nd Curly Braces: “Outputs”
3rd) Competitive Network:
In this class of neural nets the neurons are divided into two layers, the input layer, or “sources”, and the output layer, known as the “grid”.
The neurons in the lattice are forced to compete with each other, based on the level of similarity between the input pattern and the lattice of neurons, and only the winning neuron will be fired (activated) at each iteration. Nets in this class use a competitive learning algorithm.
The best-known network in this class is the Kohonen Network, also known as the Self-Organizing Map.
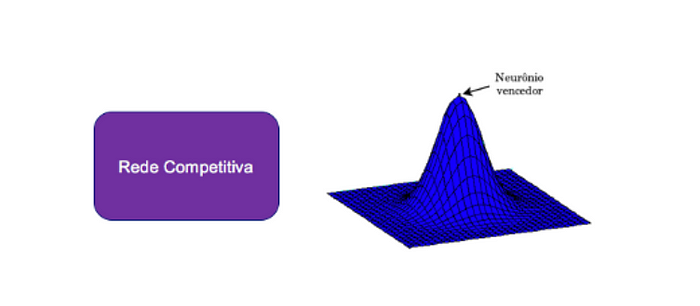
Left: CN (Competitive Networks) | Right: “Winning Neuron”
The connections between layers can generate n numbers of different structures. The way they are arranged is closely related to the learning algorithm used to train the net.
When a net has all the outputs of neurons in one layer connected to all neurons in the next layer, it is called a tightly connected or direct net.
When the output signal from a neuron serves as an input signal to one or more neurons in the same or some previous layer, the net has a characteristic called feedback.
The presence of these feedback loops has a large impact on the learning ability of the net.

Left: FFN (Direct Network) | Right: FBN (Recurrent Network)
Therefore, the architecture of the neural net is free, and can be modified as needed. This means that there is no formalization that determines how many layers, or how many neurons in the hidden layers there should be.
But there are some tools, such as the VC Dimension, that help in the theoretical analysis of the number of adjustable parameters the net should have, as a function of the number of training samples available. Note that the number of parameters defines the number of neurons.
However, usually the architecture is up to the Data Scientist, who should vary these numbers in order to achieve the best performance with a dataset reserved for testing and validation.
Until our next meeting! ;)
Vini.
____________________________________________________________________
References:
• My Original Article On Medium: Learn about the Architecture of Deep Neural Networks
• Original Font For The Article's Content: Deep Learning Book




