

KDD (Knowledge Discovery Databases)
KDD ou “Processo de Descoberta de Conhecimento”, segundo Fayyad, Piatetsky e Smyth, é um processo de várias etapas ‘não trivial’ (cada hora pode fazer de um jeito,interativo e iterativo, para a identificação de padrões compreensíveis, válidos, novos e potencialmente úteis a partir do conjunto de dados.
A caracteristica ‘não trivial’ diz respeito a complexidade existente na execução e manutenção dos processos de KDD, “interativo” representa a relevancia de um elemento que controle o processo, “iterativo” indica a possibilidade de repetições em qualquer parte dos processos, e “conhecimento útil” indica que o objetivo foi alcançado.
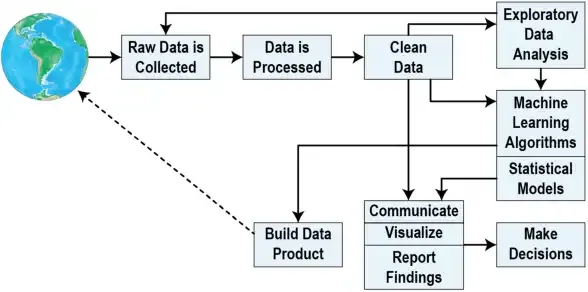
Geralmente é divido em 5 fases: Seleção, Pré-Processamento, Transformação, Data Mining e Interpretação.
Seleção:
- Consiste em pegar um conjunto ou subconjunto de dados que fará parte da análise;
- A fonte de dados pode ser variadas (planilhas, banco de dados, datawarehouse);
- Os dados podem vir em diversas estruturas (estruturado, semi-estruturados e não-estruturados).
Pré-Processamento:
- Consite em saber sobre a qualidade dos dados. Exceções e ruídos são removidos;
- Limpeza, correção e remoção de dados inconsistentes;
- Identificação de dados incompletos, não íntegros e ausentes também fazem parte do processo.
Transformação:
- Aplica técnicas de transformação como: normalização, agregação, criação de novos atributos, redução e sintetização dos dados;
- Busca-se identificar atributos úteis nos dados para alcançar os objetivos pretendidos.
Mineiração dos dados (Data Mining):
- Aplicação de algoritmos e técnicas para identificar padrões nos dados e verificar hipóteses.
- Geralmente as descobertas podem ser descritivas ou preditivas, com os seguintes objetivos:
- Regressão (uma função que faça o mapeamento dos dados);
- Clusterização (identificar um conjunto finito de categorias ou clusters);
- Sumarização (busca uma descrição compacta para o subconjunto de dados);
- Dependências ou Associações (encontrar dependencias significativas entre as variáveis);
- Divergências (encontrar alterações significativas entre os valores medidos).
Interpretação:
- Consiste em fazer a avaliação do desempenho do modelo, ocorrendo a consolidação do conhecimento descoberto.
- A avaliação pode ser feita com base na análise de profissionais ou em comparação com dados coletados anteriormente.
Espero que você tenha aprendido um pouco hoje. Sinta-se à vontade para deixar uma mensagem se tiver algum feedback e compartilhar com qualquer pessoa que possa achar isso útil.




