

EXPLORANDO A FUNÇÃO try NO PYTHON: ESTRATÉGIAS AVANÇADAS PARA TRATAMENTO DE EXCEÇÕES EM ENGENHARIA DE DADOS
- #Python
Fala Galera da DIO, como vocês estão?
A algum tempo não publico artigos e resolvi participar da primeira competição do ano. E eu não podia deixar passar a oportunidade de falar de python, a linguagem que me levou longe e vai levar ainda mais.
Para hoje resolvi falar da função "try", que é uma peça fundamental para qualquer engenheiro de dados, porem eu não a vejo sendo tão bem utilizada. Ai vem a pergunta: Quando usar a função try? fique aqui e acompanhe para entender melhor.
O uso desta função serve para lidar com complexidade e a imprevisibilidade dos dados. Aqui vamos explorar as nuances da função try em python, destacando estratégias para tratamento de exceções em ambientes de engenharia de dados. Vou mostrar aqui como essa funcionalidade traz robustez, legibilidade e uma melhor manutenção do pipeline de dados.
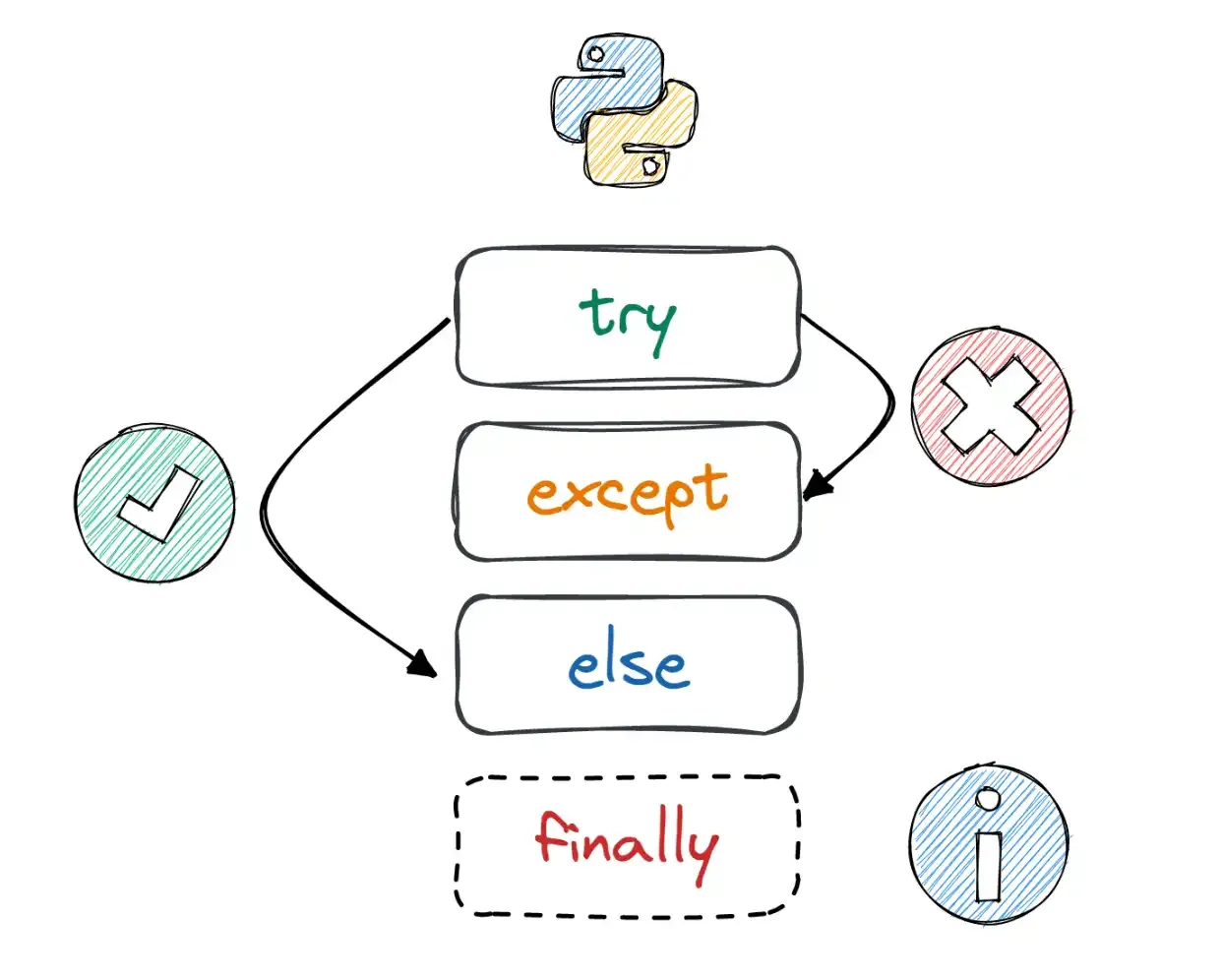
Quase ia me esquecendo, não da pra falar de try sem citar: except, else, finally e logging. Mas fiquem tranquilos o foco é no try.
No meu dia a dia como engenheiro de dados encontro diversos desafios relacionados a qualidade, consistência e integridade dos dados que recebo de forma bruta. A função em questão permite que o código se recupere do erro de maneira eficaz, evitando falhas catastróficas e continuas. Garantindo a continuidade da operação.
Técnicamente o try é: A instrução try especifica manipuladores de exceção e/ou código de limpeza para um grupo de instruções. (fonte: https://docs.python.org/pt-br/3/reference/compound_stmts.html#the-try-statement)
E como funciona o except?
A(s) cláusula(s) except especifica(m) um ou mais manipuladores de exceção. Quando nenhuma exceção ocorre na cláusula try, nenhum manipulador de exceção é executado. Quando ocorre uma exceção no conjunto try, uma busca por um manipulador de exceção é iniciada. Esta pesquisa inspeciona as cláusulas except sucessivamente até que seja encontrada uma que corresponda à exceção. (fonte: https://docs.python.org/pt-br/3/reference/compound_stmts.html#the-try-statement)
Bloco Try e Estrutura Geral:
O bloco try é utilizado para envolver código que pode gerar exceções. Quando uma exceção entra no bloco do try, o controle é transferido para o bloco except, permitindo que de para tratar a excessão de maneira adequada. O que também nos leva a pensar que podemos tratar diversas exceções de forma hierárquica. Sua estrutura geral está abaixo:
try:
# Código que pode gerar exceções
...
except ExcecaoTipo1 as e1:
# Tratamento para ExcecaoTipo1
...
except ExcecaoTipo2 as e2:
# Tratamento para ExcecaoTipo2
...
else:
# Código a ser executado se nenhum erro ocorrer
...
finally:
# Código a ser executado sempre, independentemente de ocorrerem exceções ou não
...
Com a ideia do que é o try e o except vamos agora para um exemplo real. O problema é o seguinte:
"Precisa ser lido um arquivo CSV diariamente e a inserção desses dados do arquivo CSV deve ocorrer em uma tabela de um banco de dados a sua escolha. Como utilizar exceções para lidar com possíveis erros, como a falta do arquivo ou problemas na conexão com o banco de dados?"
import csv
import sqlite3
def processar_dados_arquivo(arquivo):
try:
# Tentativa de abrir e ler o arquivo CSV
with open(arquivo, 'r') as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader) # Supondo que a primeira linha seja o cabeçalho
# Processamento dos dados (simulado)
for linha in csv_reader:
# Simulação de processamento dos dados
print(f"Processando linha: {linha}")
except FileNotFoundError as e:
# Tratamento para o caso em que o arquivo não é encontrado
print(f"Erro: Arquivo {arquivo} não encontrado. Detalhes: {e}")
except csv.Error as e:
# Tratamento para erros relacionados ao processamento do arquivo CSV
print(f"Erro ao processar o arquivo CSV. Detalhes: {e}")
else:
# Código a ser executado se nenhum erro ocorrer durante a leitura do arquivo
print("Leitura do arquivo concluída com sucesso.")
finally:
# Código a ser executado sempre, independentemente de ocorrerem exceções ou não
print("Finalizando processamento do arquivo.")
def inserir_dados_banco():
try:
# Conexão simulada com um banco de dados SQLite (criação em memória)
connection = sqlite3.connect(':memory:')
cursor = connection.cursor()
# Simulação de criação de tabela
cursor.execute('''CREATE TABLE IF NOT EXISTS dados (
id INTEGER PRIMARY KEY,
nome TEXT,
idade INTEGER
)''')
# Simulação de inserção de dados
cursor.execute("INSERT INTO dados (nome, idade) VALUES (?, ?)", ('Alice', 25))
cursor.execute("INSERT INTO dados (nome, idade) VALUES (?, ?)", ('Bob', 30))
except sqlite3.Error as e:
# Tratamento para erros relacionados ao banco de dados
print(f"Erro ao interagir com o banco de dados. Detalhes: {e}")
else:
# Código a ser executado se nenhum erro ocorrer durante a interação com o banco de dados
print("Inserção de dados no banco de dados concluída com sucesso.")
finally:
# Código a ser executado sempre, independentemente de ocorrerem exceções ou não
connection.commit()
connection.close()
print("Finalizando interação com o banco de dados.")
# Exemplo de utilização
arquivo_csv = 'dados.csv'
processar_dados_arquivo(arquivo_csv)
inserir_dados_banco()
Acima temos um código que simula a leitura de um arquivo CSV e a inserção dos dados em um banco de dados SQLite. Os blocos try, except, else e finally são usados para tratar possíveis exceções ao longo do processo, fornecendo uma abordagem robusta na manipulação de dados.
Agora vamos avançar nas técnicas para engenharia de dados:
O que iremos ver agora:
Loggin e Monitoramento
Incorporar o logging detalhado no bloco except é crucial para rastrear e entender as exceções. Além disso, implementar mecanismos de monitoramento para alertar automaticamente quando exceções críticas acontecem, assim o responsável pode ter uma resposta proativa para o problema.
Estrutura Geral:
import logging
try:
# Código suscetível a exceções
...
except ExcecaoTipo as e:
# Tratamento para a exceção
logging.error(f"Exceção capturada: {str(e)}")
# Lógica adicional de recuperação ou notificação
...
Aplicando o logging ao exemplo anterior:
import csv
import sqlite3
import logging
logging.basicConfig(level=logging.ERROR) # Configura o logging para registrar mensagens de erro ou acima
def processar_dados_arquivo(arquivo):
try:
# Tentativa de abrir e ler o arquivo CSV
with open(arquivo, 'r') as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader) # Supondo que a primeira linha seja o cabeçalho
# Processamento dos dados (simulado)
for linha in csv_reader:
# Simulação de processamento dos dados
print(f"Processando linha: {linha}")
except FileNotFoundError as e:
# Tratamento para o caso em que o arquivo não é encontrado
logging.error(f"Erro: Arquivo {arquivo} não encontrado. Detalhes: {e}")
except csv.Error as e:
# Tratamento para erros relacionados ao processamento do arquivo CSV
logging.error(f"Erro ao processar o arquivo CSV. Detalhes: {e}")
else:
# Código a ser executado se nenhum erro ocorrer durante a leitura do arquivo
print("Leitura do arquivo concluída com sucesso.")
finally:
# Código a ser executado sempre, independentemente de ocorrerem exceções ou não
print("Finalizando processamento do arquivo.")
def inserir_dados_banco():
try:
# Conexão simulada com um banco de dados SQLite (criação em memória)
connection = sqlite3.connect(':memory:')
cursor = connection.cursor()
# Simulação de criação de tabela
cursor.execute('''CREATE TABLE IF NOT EXISTS dados (
id INTEGER PRIMARY KEY,
nome TEXT,
idade INTEGER
)''')
# Simulação de inserção de dados
cursor.execute("INSERT INTO dados (nome, idade) VALUES (?, ?)", ('Alice', 25))
cursor.execute("INSERT INTO dados (nome, idade) VALUES (?, ?)", ('Bob', 30))
except sqlite3.Error as e:
# Tratamento para erros relacionados ao banco de dados
logging.error(f"Erro ao interagir com o banco de dados. Detalhes: {e}")
else:
# Código a ser executado se nenhum erro ocorrer durante a interação com o banco de dados
print("Inserção de dados no banco de dados concluída com sucesso.")
finally:
# Código a ser executado sempre, independentemente de ocorrerem exceções ou não
connection.commit()
connection.close()
print("Finalizando interação com o banco de dados.")
# Exemplo de utilização
arquivo_csv = 'dados.csv'
processar_dados_arquivo(arquivo_csv)
inserir_dados_banco()
O logging é configurado para registrar mensagens de erro. As mensagens de erro geradas pelas exceções são então registradas utilizando "logging.error", o que nos dá uma trilha para poder fazer verificações em caso de problemas durante a execução do código. Para a engenharia de dados está ferramenta é crucial, ou por um acaso você quer deixar a área de negócio da empresa sem as informações necessárias por muito tempo? Pense nisso....
Reconexão e Retentativas:
No nosso árduo trabalho diário é comum lidar com operações de rede, como conexões a banco de dados ou serviços externos. Utilizar o bloco try para implementar lógicas de reconexão pode aumentar a disponibilidade do dado.
Estrutura Geral:
import time
max_retries = 3
retry_delay = 5
for _ in range(max_retries):
try:
# Código que pode gerar exceções de conexão
...
except ExcecaoDeConexao:
logging.warning("Falha na conexão. Tentando novamente...")
time.sleep(retry_delay)
else:
break # Se a execução for bem-sucedida, saia do loop de retentativas
Aplicando o retry ao exemplo anterior:
Agora estou simulando um cenário em que a conexão com o banco pode falhar, e estamos tentando novamente por um número máximo de vezes, com um atraso entre as tentativas. Vamos adicionar essa lógica ao código existente:
import csv
import sqlite3
import logging
import time
logging.basicConfig(level=logging.ERROR) # Configura o logging para registrar mensagens de erro ou acima
def processar_dados_arquivo(arquivo):
try:
# Tentativa de abrir e ler o arquivo CSV
with open(arquivo, 'r') as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader) # Supondo que a primeira linha seja o cabeçalho
# Processamento dos dados (simulado)
for linha in csv_reader:
# Simulação de processamento dos dados
print(f"Processando linha: {linha}")
except FileNotFoundError as e:
# Tratamento para o caso em que o arquivo não é encontrado
logging.error(f"Erro: Arquivo {arquivo} não encontrado. Detalhes: {e}")
except csv.Error as e:
# Tratamento para erros relacionados ao processamento do arquivo CSV
logging.error(f"Erro ao processar o arquivo CSV. Detalhes: {e}")
else:
# Código a ser executado se nenhum erro ocorrer durante a leitura do arquivo
print("Leitura do arquivo concluída com sucesso.")
finally:
# Código a ser executado sempre, independentemente de ocorrerem exceções ou não
print("Finalizando processamento do arquivo.")
def inserir_dados_banco():
for tentativa in range(1, max_retries + 1):
try:
# Conexão simulada com um banco de dados SQLite (criação em memória)
connection = sqlite3.connect(':memory:')
cursor = connection.cursor()
# Simulação de criação de tabela
cursor.execute('''CREATE TABLE IF NOT EXISTS dados (
id INTEGER PRIMARY KEY,
nome TEXT,
idade INTEGER
)''')
# Simulação de inserção de dados
cursor.execute("INSERT INTO dados (nome, idade) VALUES (?, ?)", ('Alice', 25))
cursor.execute("INSERT INTO dados (nome, idade) VALUES (?, ?)", ('Bob', 30))
except sqlite3.Error as e:
# Tratamento para erros relacionados ao banco de dados
logging.erro
O código de retentativas foi integrado á lógica de interação com o banco de dados. O número máximo de retentativas (max_retries) e o atraso entre uma tentativa e outra (retry_delay) são definidos no início do script. O código tentará fazer a conexão com o banco de dados até que tenha sucesso ou atinja o numero máximo de retentativas. O logging é utilizado para registrar mensagens informativas sobre o progresso e os erros encontrados durante as tentativas de conexão.
Esse cenário acima é um simplista e considerando somente uma tabela pequena, olhando por esse lado parece até inutil todo essse refinamento, porem no final do dia de trabalho esse refinamento no código te salva de horas de debugging
A função try no Python é uma ferramenta versátil e poderosa que os engenheiros de dados podem aproveitar para fortalecer a robustez de seus pipelines. Ao incorporar estratégias avançadas, como logging detalhado e retentativas, é possível criar sistemas mais resilientes e confiáveis.






