

Entendendo versionamento de código distribuído e centralizado
- #Git
O que é versionamento de código?
A partir do momento em que um projeto passa a ser feito por duas ou mais pessoas esse projeto fica sujeito a ter “duas faces”, isto é, versões diferentes que estão sendo manipuladas simultaneamente.
Gerenciar um projeto nessa situação pode ser uma tarefa difícil, uma vez que se faz necessário dividir atenção entre as versões, o que demanda um tempo precioso que poderia estar sendo dedicado á codificação do projeto. Essa situação desagradável se torna ainda mais difícil e obscura quando lidamos com a necessidade de ver o que aconteceu em determinado ponto, no passado, dos código. Essa consulta de versão se torna, por vezes, inviável.
Para resolver esse problema e outros advindos do mau gerenciamento das versões, os desenvolvedores começaram a usar diversas técnicas para comparar arquivos, guardar estados anteriores, unir arquivos diferentes e monitorar um repositório (pasta de arquivos principal).
Essas técnicas culminaram no advento de diversas ferramentas, essas ferramentas foram aperfeiçoadas e o desenvolvedor Linus Benedict Torvalds (principalmente ele), junto com alguns amigos chegou ao sistema de versionamento de código conhecido por Git, que combina os métodos usados para gerenciar repositórios, já conhecidos, mas trás como diferencial alto desempenho e confiabilidade, além de ser distribuído e open source.
Sistemas de Versionamento de Código Centralizados vs Distribuídos
Ao pensar que vários desenvolvedores estão trabalhando num mesmo projeto é fácil imaginar que há um local comum usado para armazenar os arquivos codificados, em um sistema centralizado isso ocorre em um local na nuvem, com atenção especial nesse “um”, pois o repositório do projeto propriamente dito se encontra ao alcance de todos, geralmente configurado como um servidor de nuvem, permitindo o acesso aos seus arquivos através de uma conexão com a internet.
Não acho que você notou o problema por trás disso, mas provavelmente é porque não há, até a situação atual, afinal temos um local comum aonde a equipe pode acessar, baixar o projeto - até sua versão atual - e realizar a suas modificações.
Geralmente temos o seguinte fluxo de trabalho com CVCSs (Centralized Version Control Systems): baixar o repositório, contribuir no projeto e subir suas alterações, de forma que apenas nessa última etapa você registra um ponto na história desse projeto.
Mas imagine que você implementa novas funcionalidades em um software de vendas, por exemplo, baixa no estoque e lista de reposição do estoque, entretanto, logo depois de subir suas atualizações é reportado um bug na geração da lista de reposição. Agora é necessário voltar uma versão, para o que antes estava funcional. Como você faria para não perder a funcionalidade de baixa no estoque?
Os VCSs centralizados registram os pontos em que recebem essas alterações em seus repositórios, implicando que cada contribuição seja um marco de versão, mas ocasionando perdas completas se necessário voltar, gerando um retrabalho para recuperar funcionalidades que já haviam sido implementadas de forma funcional.
Isso não necessariamente implica que os VCSs centralizados são ruins, mas quanto mais pessoas contribuindo em um projeto, mais difícil gerenciar de forma efetiva um repositório centralizado.
Ademais, para nós desenvolvedores, marcar alterações em um projeto, pode ser necessário em uma escala diferente das funcionalidades apresentadas no exemplo acima, podendo ser a implementação de um botão ou uma animação de um item, até mesmo uma data acrescentada ou modificada. Por isso realizar várias alterações, isto é, várias linhas de código, e perdê-las em um retorno de versão pode significar muito.
O ideal, e aqui fica uma dica, é gravar um checkpoint a cada botão, campo e modificação significativa em nível de código, para conseguir gerenciar mudanças no repositório de maneira mais eficiente. Entretanto, isso implicaria fazer diversos uploads de alterações no repositório central, a uma alta frequência. Coloque isso em uma escala maior - algo como projetos open source - e você terá um possível desastre, com vários conflitos de alterações.
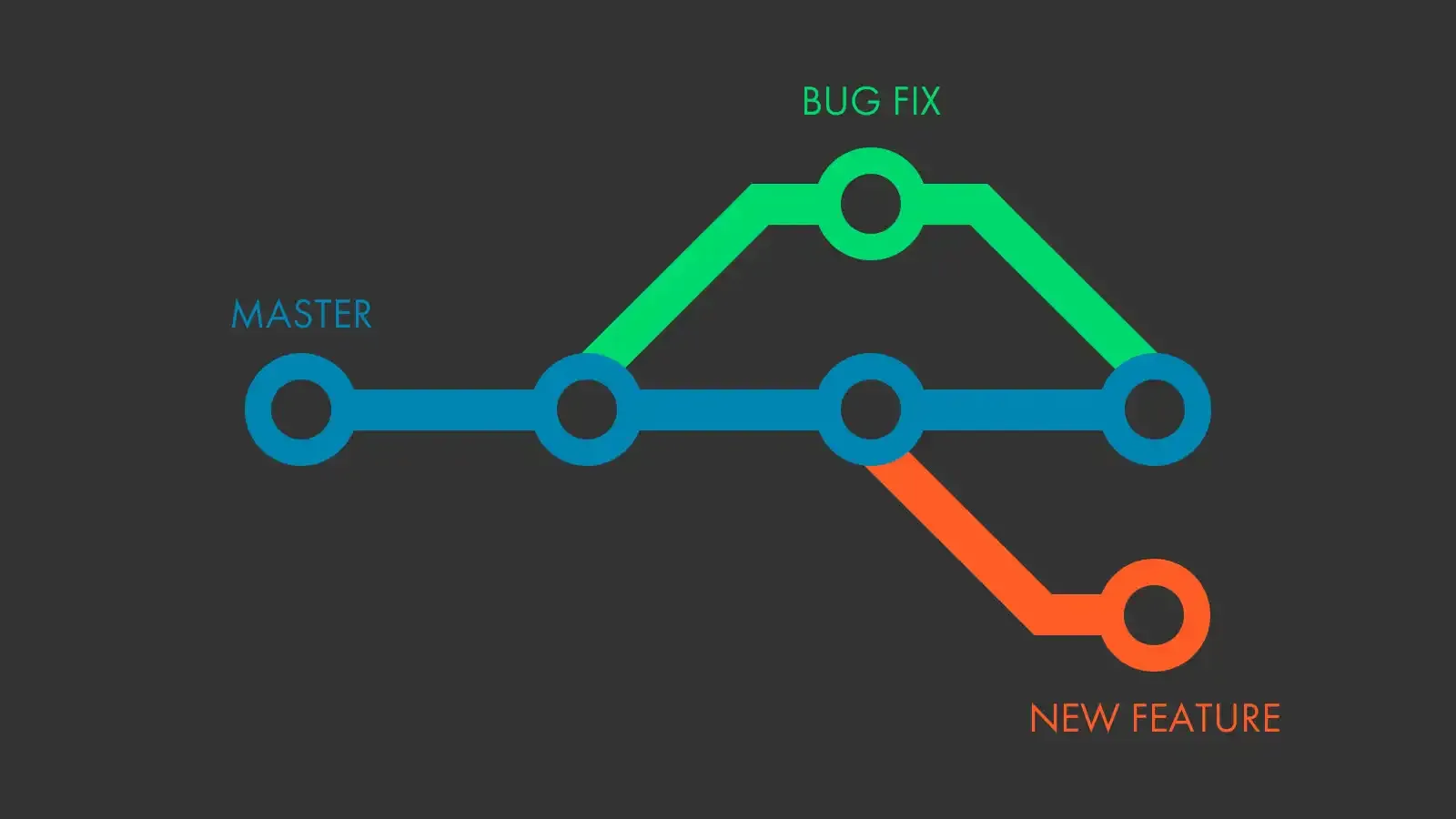
Afim de solucionar isso, o Git foi pensado para manter o repositório, de certa forma, individualizado. Permitindo que no lugar de várias pessoas acessarem o mesmo local, cada um tivesse meios de gerenciar as próprias alterações localmente e pudesse mesclar suas alterações com outras versões do mesmo projeto, versões essas pertencentes e alteradas por outras pessoas.
Fonte: Centralized vs Distributed Version Control: Which One Should We Choose? - GeeksforGeeks, Data de acesso: 04 de Junho de 2023.
Na prática, você clona um projeto e faz alterações, registrando apropriadamente cada modificação relevante, outra pessoa faz o mesmo, uma vez que resolvam retornar as novas versões para a origem. Isso é feito pelo git.
A possibilidade de haver o mesmo projeto, gerenciado localmente, em diferentes locais é o que caracteriza o versionamento distribuído, uma vez que em determinado momento cada versão é uma versão válida e diferentes entre si.
Esse ultimo fator possibilita que um mesmo software tenha várias versões válidas originadas de um mesmo repositório, sendo o exemplo mais conhecido os sistemas operacionais Linux, que atualmente são conhecidos por diversas distribuições, como Debian, Ubuntu, RedHat, Arch, Kali, etc.
O que é Git?
O Git surgiu em 2005 para ser um DVCS open source, uma vez que Linus Torvalds precisava de um DVCS para gerenciar o projeto da kernel do Linux, uma vez que o BitKeeper deixa de oferecer, em 2002, um serviço satisfatório, para as necessidades de Linus e sua equipe.
O Git é um Sistema de Versionamento de Código Distribuído (DVCS - Distributed Version Code System), que permite que cada desenvolvedor tenha uma cópia própria do repositório na sua máquina local e gerencie as próprias alterações por conta própria.
Com o Git é possível de forma confiável e rápida, através de comandos simples, realizar o registro de histórico dos arquivos, gerenciamento de alterações, organização e recuperação de informações de forma segura, permitindo ainda que modificações sejam mescladas e assim possibilitando a cooperação de times mais eficiente.
Vale ressaltar que eficiência e confiabilidade nessa ferramenta possibilitaram que tecnologias open source, que muitas vezes têm dezenas de contribuintes, alcançassem os patamares conhecidos atualmente.




