
Como otimizei um Arquivo de 1.6 GB para 9 MB usando Python
- #Python
De 22.344.848 Linhas para 247.246, exclusivamente com Pandas
Contextualizando a Situação
No meu papel como analista de dados em uma concessionária de rodovias, enfrentei recentemente o desafio de extrair dados específicos de câmeras de tráfego ao longo de um trecho crucial em São Paulo. Essas câmeras, conhecidas como SAT, registram passagem por passagem de cada veículo, fornecendo dados cruciais para nosso estudo de perfil de tráfego.
Uma demanda recente exigiu a extração de dados de alguns SATs selecionados para todo o ano de 2023. Considerando o volume de informações necessárias, sabia que enfrentaria um desafio considerável.
O Processo de Consulta
Trabalhando predominantemente com o Microsoft Power BI, decidi explorar a análise de dados com Python para esta tarefa. A ideia era extrair dados diretamente do SQL, salvá-los em CSV e enviá-los ao requisitante.
Entretanto, ao realizar a consulta no SQL Server Management Studio (SSMS), deparei-me com um desafio logístico: mais de 22 milhões de linhas foram retornadas, resultando em um arquivo CSV com 1.6 GB.
A Solução Criativa
Após uma conversa com o requisitante, percebi que a necessidade era consolidar os dados por data e hora, não manter o detalhamento passagem por passagem. Com o arquivo CSV em mãos, decidi utilizar o Python e a biblioteca Pandas para agregar os dados conforme solicitado.
Criei um Jupyter Notebook no Visual Studio Code para tratar o arquivo:
- Importação da Biblioteca
Comecei importando a biblioteca necessária para o tratamento do arquivo:

2. Carregamento do Arquivo
Em seguida, carreguei o arquivo como um dataframe do diretório de rede da empresa:
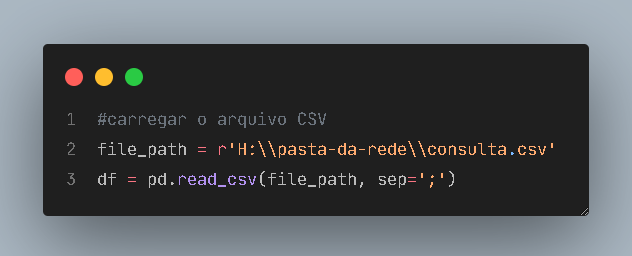
Alterei o caminho devido a informações sigilosas.
3. Criação de uma Nova Coluna com Apenas a Hora
Adicionei uma coluna ao dataframe, retendo apenas a informação da hora de cada passagem:
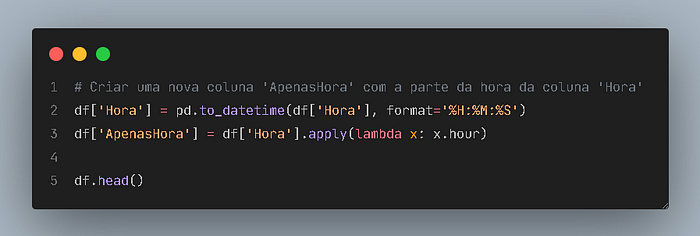
Utilizei df.head() para verificar a correta execução da tratativa.
4. Agrupamento de Dados
Após a criação da coluna com as horas, procedi com a agregação da quantidade de passagens por data, hora, tipo de veículo e sentido:

5. Salvamento do Novo Arquivo CSV
Finalmente, salvei o novo dataframe em um arquivo CSV menor, pronto para ser compartilhado:
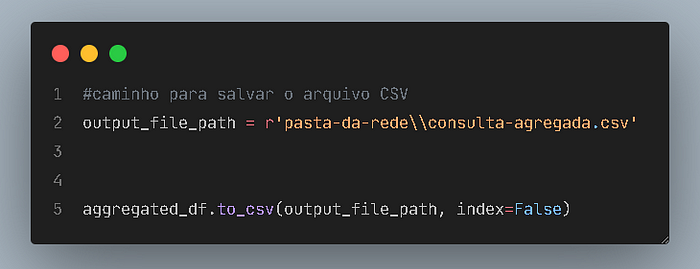
Conclusão
Essa abordagem transformou um arquivo de 22 milhões de linhas e 1.6 GB em um arquivo com cerca de 200 mil linhas e 9 MB, representando uma redução de quase 99% no tamanho.
Embora existam métodos para realizar essa agregação diretamente no SQL, esta solução com Python foi a mais eficiente dado o contexto. Se você achou essa técnica útil, compartilhe com seus colegas e deixe sua opinião nos comentários! Sua experiência pode inspirar outros profissionais da ciência de dados.




