


Como hospedar um site estático automatizado no AWS S3 usando HTML, CSS, JS e Shell Scripts no Linux Debian 12
- #AWS
- #HTML
- #JavaScript
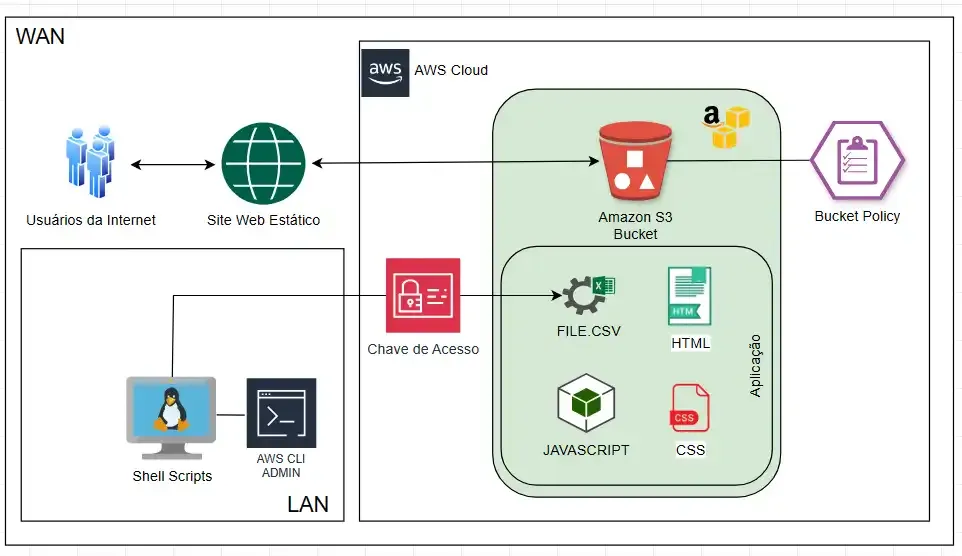
Olá, seja bem vindo(a), neste artigo eu vou compartilhar como fazer para implementar um site estático automatizado no armazenamento do Amazon S3 utilizando as tecnologias do HTML, CSS, Java Script, S3 AWS, CLI, .CSV, SHEL SCRIPT, LINUX DEBIAN, SAMBA E MICROSOFT EXCEL.

O Amazon S3
A escolha do AWS S3 para hospedar o site estático se deu pela sua confiabilidade, escalabilidade e baixíssimo custo. Além disso, a integração com a ferramenta AWS CLI permitiu a automação do processo de atualização do site, garantindo que as informações estejam sempre atualizadas.
A Aplicação Web
A função principal desta aplicação é exibir as informações atualizadas sobre os níveis hidráulicos ou alguma outra métrica semelhante através de uma página web na internet.
Para desempenhar essa atividade essa aplicação foi construída em HTML, CSS, JavaScript e sua estrutura até o momento é formada por apenas quatro pequenos arquivos que são: index.html, styles.css, main.js, target-file.csv.
O target-file.csv é o alvo por onde a aplicação lê os dados e informações sobre os horários e níveis da água para poder exibir na página web online.

Só para constar, não fui eu quem desenvolveu essa aplicação do zero, essa aplicação foi obtida em algum dos vários treinamentos gratuitos da AWS que eu realizei no passado e estou apenas reaproveitando a finalidade do código fonte para realizar esse laboratório. O arquivo fonte está disponível no meu github. https://lnkd.in/dsFB-yXn
O Servidor Local
O arquivo target-file.csv fica armazenado no bucket para ser exibido na página web na internet e também fica armazenado na rede local através de um servidor Linux utilizando o pacote Samba para compartilhar diretórios.
O Script Agendado
Utilizando um agendamento com o cron a cada 10 minutos o Linux copia e substitui o arquivo no bucket do s3 através da execução de um script de SHELL. O sistema operacional Linux pode ser executado em uma máquina virtual ou máquina física.
Os Colaboradores
Os colaboradores acessam a rede pelo compartilhamento do servidor Linux, abrem o arquivo target-file.csv pelo programa do excel e inserem os dados que serão lidos pela aplicação na página web quando o arquivo for enviado.

Como configurar na prática - Esses são os passos para configurar a aplicação na nuvem da AWS usando o serviço S3.
Passo 1: Criar e configurar um bucket s3
Primeiramente, crie um bucket no AWS S3.

Certifique-se de habilitar a hospedagem de site estático nas propriedades do bucket.

Desmarque as permissões de bloqueio de acesso público. Usaremos uma política para controlar o acesso aos objetos desse bucket.

Ainda na guia de permissões nas configurações no bucket insira a política de segurança de acesso ao bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::NOME_DO_BUCKET/*"
}
]
}
Modifique o nome do bucket criado ou crie um bucket novo.

Passo 2: Configurar o Acesso via Linha de Comandos
Vamos utilizar a linha de comandos AWS CLI para enviar os arquivos da aplicação para o bucket S3 e também para atualizar o arquivo alvo com as informações que serão exibidas na página web diariamente. Isso significa que o arquivo .csv será atualizado periodicamente com os novos dados inseridos pelos colaboradores da rede local.
Para ter acesso ao bucket precisamos de uma chave de acesso com as permissões adequadas para poder gerenciar os arquivos do site da nossa aplicação. Isso é possível utilizando a ferramenta do AWS Identity and Access Management.
Acesse o console da sua conta e abra o painel do serviço do IAM. Comece criando o usuário.

Durante a criação do usuário escolha anexar políticas diretamente



Depois de criado o usuário, acesse as configurações dele e encontre a opção Credenciais de Segurança.

Logo em seguida escolha criar chave de acesso:

Na configuração da chave de acesso do usuário criado escolha a opção CLI.

Copie as informações da chave no final da configuração e guarde as informações em um arquivo de texto.

Com a chave de acesso copiada é necessário instalar o pacote awscli no sistema operacional do servidor local e depois configurar o acesso para poder interagir com o bucket através da rede local e a AWS S3.

Depois que o pacote estiver instalado é hora de configurar a chave de acesso na ferramenta de comandos awscli informando o nome do usuário, a chave e a região onde o bucket foi criado.

Com o comando cat do Linux verifique se as credenciais foram mesmo inseridas nas configurações da ferramenta awscli.

Depois de configurada a chave de acesso já é possível listar os buckets do serviço de armazenamento de objetos AWS S3 com comando “aws s3 ls”.

Passo 4: Upload dos arquivos
Depois de validar o acesso ao AWS S3 com a chave criada é necessário enviar os arquivos da aplicação para o bucket.
Para isso baixe o arquivo original no meu repositório do GitHub: https://github.com/ralexandrecode/labcode_s3/archive/refs/heads/main.zip

Descompacte o arquivo baixado e verifique se os arquivos estão corretos.

Acesse o diretório criado com os arquivos da aplicação.

Execute o comando awscli para enviar todos os arquivos de uma só vez:

Observe que os dados da aplicação estão originais ainda, exibindo o texto em inglês, então, se quiser modificar, altere os arquivos main.js e o index.html assim como mostra as imagens a seguir.
Altere os textos nas linhas 16 e 27 do arquivo main.js

Altere o arquivo index.html nas linhas 8 e 14 como a seguir.

Recupere a URL do arquivo index.html e faça o acesso à aplicação.

Cole o endereço no navegador e veja a aplicação online funcionando.

Passo 5: Compartilhar o arquivo alvo na rede
Para que os colaboradores possam inserir informações dos níveis de água é necessário compartilhar o arquivo na rede local.
Para isso instale o pacote samba no servidor Linux. Como observação, esse processo também pode ser feito em sistemas operacionais Windows.

Configure o samba para compartilhar um diretório através do arquivo principal smb.conf.

Neste caso configurei um diretório a ser acessado somente por um usuário chamado de aluno. Mas fique a vontade para configurar o compartilhamento da melhor forma possível para você.
Reinicie o serviço do samba e confira se está rodando corretamente.


Configure o usuário e senha para acesso ao compartilhamento pelo samba.

Verifique se o usuário foi criado.

Crie o diretório e coloque as permissões adequadas de acesso para os colaboradores.

Copie o arquivo alvo para o diretório criado anteriormente para ser compartilhado na rede.

Agora coloque permissões de escrita no arquivo alvo.

Teste o acesso de outra máquina na rede entrando com IP ou nome do servidor.

Entre com o usuário e a senha criados anteriormente.

Obtenha acesso ao arquivo compartilhado.

Abra o arquivo usando o Excel e veja que na coluna A é onde estão as informações que serão lidas pela aplicação.

E pronto. A partir de agora os colaboradores responsáveis por alimentar o arquivo alvo com os dados poderão acessar ele pela rede utilizando as credenciais de usuário e senha.
Passo 6: Criar um script de shell
Neste passo vamos criar um script que sincronize o arquivo compartilhado na rede local com o arquivo que é lido pela aplicação dentro do bucket do S3.
Crie um arquivo com as seguintes linhas e depois salve.
#!/bin/bash
aws s3 cp /mnt/arquivos/target-file.csv s3://bucket002026/

No caso do Linux, coloque permissão de execução.

Teste a execução do arquivo.

Pronto! Agora é só inserir as informações no arquivo alvo, salvá-lo, e depois executar o script para sobrescrever o arquivo original no bucket do S3 atualizando assim as informações.

Passo 7: Automatizar a execução do script
Para que as informações inseridas no arquivo alvo estejam sempre atualizadas no bucket onde a aplicação está hospedada é necessário agendar uma tarefa no Linux utilizando o programa padrão CRON.
A regularidade da atualização vai depender de cada situação, mas para esse exemplo eu configurei o CRON para executar o arquivo de script a cada uma hora todos os dias da semana.
*/60 * * * * /root/./script.sh

Passo 8: Acessar a aplicação pela URL gerada pelo S3
Por fim, agora é só acessar a aplicação de site estático através da URL gerada pelo Amazon S3 pelo navegador web e ver as informações atualizadas sobre os níveis da água ou reservatórios que possam ser monitorados. https://bucket002026.s3.amazonaws.com/index.html

Conclusão
Essa aplicação demonstrou a viabilidade de um sistema de monitoramento de nível de água em tempo real que coleta dados de arquivos CSV compartilhados em uma rede local. O sistema é fácil de implementar e manter, e fornece informações precisas e atualizadas sobre os níveis de água.
Aplicação Executando:
https://bucket002026.s3.amazonaws.com/index.html
Código Fonte Original:
https://github.com/ralexandrecode/labcode_s3/archive/refs/heads/main.zip
Vídeo no Youtube:
https://youtu.be/zvU3Le2EN7c
#awssolutionsarchitect #awss3 #awscli #linux #debian12 #shellscript #awscertifications






