
Aprendizado Não Supervisionado: Uma Abordagem Essencial em Machine Learning
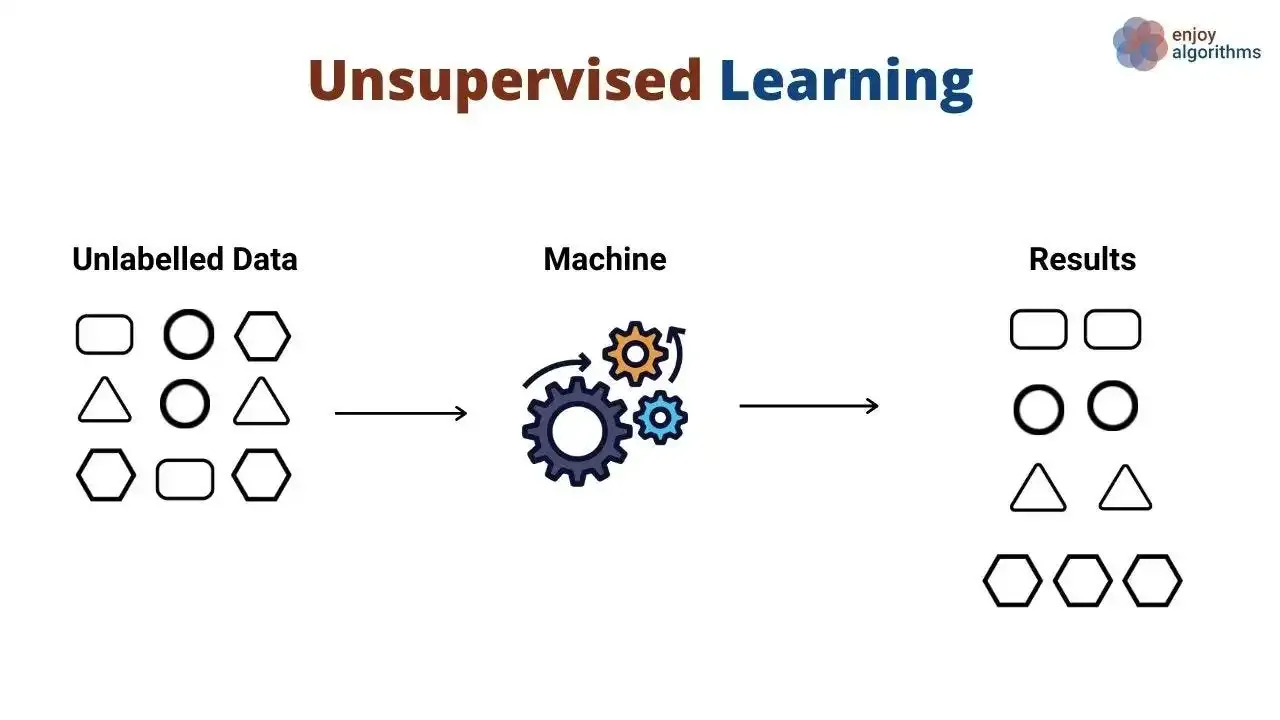
O aprendizado não supervisionado é uma das técnicas mais fascinantes e desafiadoras no campo de Machine Learning (ML). Diferente do aprendizado supervisionado, onde os algoritmos são treinados com dados rotulados, o aprendizado não supervisionado trabalha com dados não rotulados, tentando encontrar padrões ou estruturas intrínsecas nos dados. Esta técnica é particularmente relevante em Ciência de Dados, Visão Computacional e outras áreas que lidam com grandes volumes de dados sem rótulos prévios.
Conceitos Fundamentais e Definições
Aprendizado Não Supervisionado
O aprendizado não supervisionado refere-se a métodos de aprendizado de máquina que procuram identificar padrões em dados sem referências ou rótulos conhecidos. Ao invés de prever um valor ou categoria específica, esses métodos tentam descobrir a estrutura subjacente dos dados.
Clustering (Agrupamento)
Clustering é uma técnica comum de aprendizado não supervisionado, que envolve a segmentação de um conjunto de dados em subgrupos ou clusters, de forma que os dados em cada cluster sejam mais semelhantes entre si do que aos dados em outros clusters. Algoritmos populares de clustering incluem K-means, Hierarchical Clustering e DBSCAN.
Redução de Dimensionalidade
A redução de dimensionalidade é o processo de reduzir o número de variáveis aleatórias sob consideração, obtendo um conjunto de principais variáveis. Técnicas como Principal Component Analysis (PCA) e t-Distributed Stochastic Neighbor Embedding (t-SNE) são amplamente usadas para este fim.
Regras de Associação
Regras de associação são usadas para encontrar relacionamentos interessantes entre variáveis em grandes bases de dados. O algoritmo Apriori é um dos métodos mais conhecidos nesta categoria.
Anomalia (Detecção de Anomalias)
A detecção de anomalias visa identificar padrões em dados que não correspondem ao comportamento esperado. Este método é amplamente utilizado para detectar fraudes, defeitos e outras irregularidades.
Aplicações Práticas e Exemplos de Uso
Segmentação de Clientes
Uma aplicação prática de clustering é a segmentação de clientes em marketing. Utilizando algoritmos como K-means, empresas podem agrupar clientes com base em comportamentos de compra, permitindo campanhas de marketing mais direcionadas e eficazes.
from sklearn.cluster import KMeans
import numpy as np
# Exemplo de dados de clientes (idade, gasto anual)
data = np.array([[25, 40000], [34, 58000], [22, 55000], [35, 20000], [45, 78000]])
# Aplicação de K-means
kmeans = KMeans(n_clusters=2, random_state=0).fit(data)
print(kmeans.labels_)
Compressão de Dados
A redução de dimensionalidade com PCA é frequentemente usada para compressão de dados, permitindo a visualização de dados de alta dimensionalidade em duas ou três dimensões.
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Dados de exemplo
data = np.random.rand(100, 5)
# Aplicação de PCA
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
# Visualização dos dados reduzidos
plt.scatter(reduced_data[:, 0], reduced_data[:, 1])
plt.show()
Detecção de Fraudes
Na detecção de fraudes, algoritmos de detecção de anomalias são utilizados para identificar transações suspeitas. Modelos como Isolation Forest e Local Outlier Factor são populares nessa área.
from sklearn.ensemble import IsolationForest
# Dados de transações
data = np.random.rand(100, 2)
# Aplicação de Isolation Forest
clf = IsolationForest(random_state=0).fit(data)
outliers = clf.predict(data)
print(outliers)
Desafios e Considerações Importantes
Interpretação dos Resultados
Um dos maiores desafios do aprendizado não supervisionado é a interpretação dos resultados. Sem rótulos claros, pode ser difícil determinar se os agrupamentos ou padrões identificados são realmente significativos.
Determinação do Número de Clusters
Em técnicas de clustering, decidir o número de clusters apropriados pode ser complicado. Métodos como a soma das distâncias quadradas dentro dos clusters (método do cotovelo) e o coeficiente de silhueta são utilizados para ajudar na determinação.
Escalabilidade
Algoritmos de aprendizado não supervisionado podem ser computacionalmente intensivos, especialmente com grandes volumes de dados. A escalabilidade dos algoritmos é uma consideração importante, exigindo otimizações e técnicas de processamento distribuído.
Overfitting
Embora o overfitting seja mais associado ao aprendizado supervisionado, ele também pode ocorrer no aprendizado não supervisionado. Técnicas como validação cruzada e regularização são necessárias para mitigar esse problema.
Conclusão e Visão Futura
O aprendizado não supervisionado continuará a ser uma área vital de pesquisa e aplicação em Machine Learning. À medida que os volumes de dados crescem, a capacidade de encontrar padrões e insights sem supervisão humana será cada vez mais valiosa. Ferramentas e algoritmos mais sofisticados, aliados ao poder computacional crescente, permitirão que o aprendizado não supervisionado seja aplicado a problemas mais complexos e em maior escala.
Visão Futura
A integração de aprendizado não supervisionado com técnicas de aprendizado supervisionado (aprendizado semi-supervisionado) é uma área promissora, oferecendo o melhor dos dois mundos. Além disso, avanços em técnicas de deep learning não supervisionado, como Autoencoders e GANs (Generative Adversarial Networks), abrirão novas possibilidades para a descoberta de padrões e a geração de dados sintéticos.
Em resumo, o aprendizado não supervisionado é uma ferramenta poderosa no arsenal de um cientista de dados, permitindo a descoberta de insights valiosos em dados brutos e não rotulados. Com a evolução contínua das tecnologias e algoritmos, o potencial para aplicações inovadoras continuará a expandir, transformando diversos setores da indústria e da pesquisa.





