
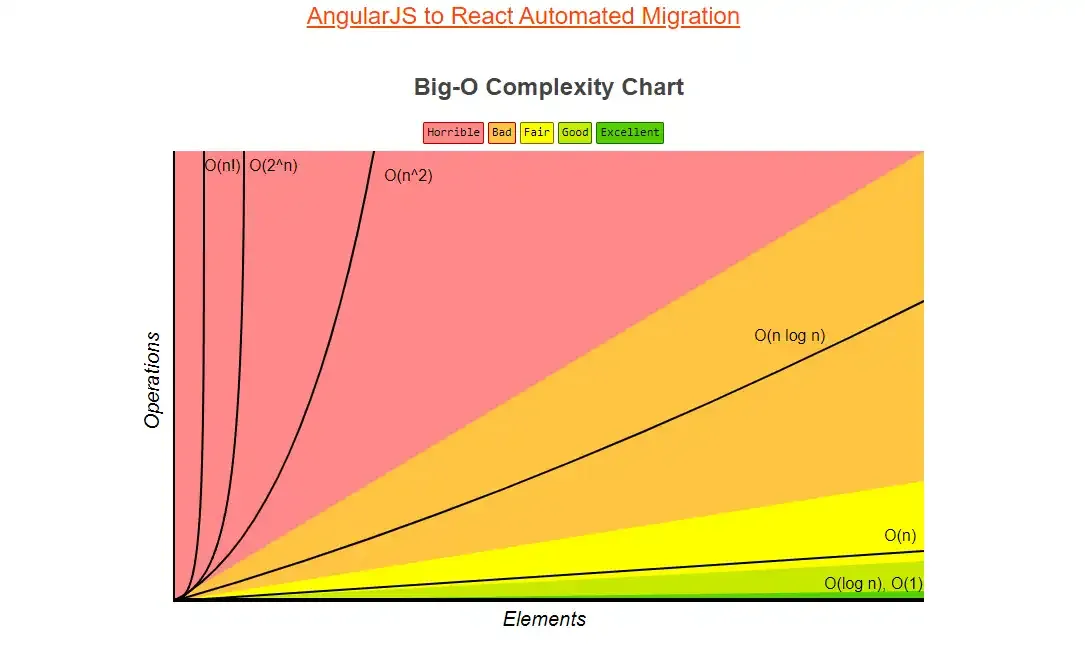

Abstraindo a performance de um algoritmo.
- #Kotlin
- #SQL
- #Java
Estava analisando a complexibilidade de um código com as collection do java e fazendo um debbug para poder estudar a sua complexidade e essa foi minha abstração a respeito:
Estou usando uma ArrayList e usei dois métodos dessa coleção.
A primeira é o .contains() e segunda é o .get().
Vamos imaginar um cenário onde exista uma lista de 10 milhões de smartphones, é uma lista muito alta correto?
eu usando o .contains (com o equals da classe smartphone, sobrescrito) para procurar um aparelho dentro do ArrayList, ela vai me retornar o aparelho específico que pedi para trazer, ou seja, ela irá percorrer toda a lista até achar o aparelho específico, em questão de performance da complexidade big O para a procura(search) ela seria o (O(n)) já esta laranja;amarela. Nessa lista ia ter um tempo muito longo se o smartphone estivesse no último índice, concordam comigo?
O ArrayList, tem uma performance melhor no método .get(). (o(1)) porque ela já vai direto ao ponto onde o aparelho está se passarmos dentro do parâmetro do .get(indiceSmarthphone9999999) ela vai diretamente para o aparelho, sem precisar percorrer toda a arrayList.
Mas Rodrigo, como deixar performático esse o método .contains() sem precisar passar o índice? Mudando a estrutura de dados, para uma mais performática dentro do contexto dessa especificidade, que seria a estrutura Set como por exemplo uma lista do tipo hashSet. Baseado novamente na sobrescrita do método equals() e agora também com a sobrescrita do metodo hash(), ele não precisará percorrer toda a lista para encontrar o produto diretamente. Deixando a complexidade (o(1)).
Como eu usaria o método .contains() em um sistema real?
Vamos dar um exemplo que estamos adicionando aparelhos com seus respectivos serialNumbers no estoque que todo aparelho celular tem. No mundo real, não existem dois aparelhos com o mesmo SerialNumber, mas como humanos nós somos falhos. Se hipoteticamente no estoque a gente adicionar o mesmo serialNumbers, nós podemos evitar esse problema fazendo uma validação com o método contains(), verificando se aquele serialNumber ja foi inserido. Assim evitando a duplicação dentro do estoque.



Alguns links para estudos
Complexidade big O https://lnkd.in/eEDW2bdu
Complexidade na Collection do Java: https://lnkd.in/e5Zq_49s
Equals e hashCode: https://lnkd.in/dMjrJzC4





