


Desvendando os Mistérios da Linguagem: Uma Jornada pelo CLM e Classificação de Sentenças/Tokens
A linguagem humana, com suas nuances e complexidades, sempre fascinou e desafiou os cientistas da computação. No entanto, com o avanço da Inteligência Artificial, ferramentas como o Processamento de Linguagem Natural (PNL) estão nos permitindo não apenas entender, mas também gerar e manipular linguagem de maneiras surpreendentes. Nesta jornada, exploraremos dois pilares do PNL: Causal Language Modeling (CLM) e Classificação de Sentenças/Tokens, mergulhando em seus mecanismos técnicos e revelando seu potencial transformador.
Causal Language Modeling (CLM): Uma Máquina de Escrever com Memória Seletiva
Imagine uma máquina de escrever mágica que, ao digitar uma palavra, sugere a próxima com base em tudo o que já foi escrito. Essa é a essência do CLM, onde modelos de linguagem aprendem a prever a próxima palavra em uma sequência, considerando apenas o contexto anterior. É como se o modelo tivesse uma memória seletiva, focando no passado para moldar o futuro da narrativa. Essa abordagem, conhecida como modelagem autorregressiva, é fundamental para a geração de texto coerente e criativo (Radford et al., 2019).
Como a Mágica Acontece?
- Tokenização: Desmontando o Quebra-Cabeça da Linguagem
Assim como um quebra-cabeça é composto por peças individuais, o texto é dividido em unidades menores, como palavras ou subpalavras, chamadas tokens. Esse processo, conhecido como tokenização, permite que o modelo lide com a linguagem de forma estruturada e é um passo crucial na preparação de dados para PNL (Jurafsky & Martin, 2023).
- Sequências: A Ordem dos Fatores Altera o Produto
Os tokens são organizados em sequências, onde cada token é previsto com base nos tokens anteriores. Imagine que você está lendo um livro: cada palavra que você lê influencia sua expectativa sobre a próxima, certo? O CLM funciona da mesma forma, aprendendo a reconhecer padrões e dependências entre as palavras para gerar sequências textuais fluentes e contextualmente relevantes (Brown et al., 2020).
- Treinamento: Aprendendo com Exemplos
O modelo é alimentado com grandes quantidades de texto, como livros, artigos e conversas. A cada palavra prevista, ele compara sua previsão com a palavra real e ajusta seus parâmetros internos para minimizar erros. É como um aprendiz que aprimora suas habilidades com a prática. Esse processo iterativo de treinamento é essencial para o aprendizado de representações robustas da linguagem pelo modelo (Bengio et al., 2003).
- Mecanismos de Atenção: Focando no que Importa
Imagine que você está tentando lembrar o que comeu no café da manhã. Você não precisa se lembrar de tudo o que aconteceu na semana para acessar essa informação, certo? Da mesma forma, os mecanismos de atenção permitem que o modelo foque em partes específicas do contexto anterior que são mais relevantes para a previsão da próxima palavra, ignorando informações menos importantes. Essa capacidade de selecionar informações contextuais relevantes é crucial para a modelagem de relações complexas dentro do texto (Vaswani et al., 2017).
- Transformers: A Revolução da Arquitetura
Os Transformers são modelos de linguagem que revolucionaram o CLM. Eles permitem o processamento paralelo de informações, o que significa que o modelo pode analisar diferentes partes do texto simultaneamente, capturando relações de longo alcance entre as palavras de forma mais eficiente. Essa arquitetura inovadora levou a avanços significativos na qualidade e fluência do texto gerado por modelos de linguagem (Vaswani et al., 2017).
Vantagens:
- Criatividade: CLM permite a geração de texto de forma livre e criativa, aprendendo padrões complexos da linguagem.
- Contextualização: A capacidade de considerar o contexto anterior torna o texto gerado mais coerente e relevante.
Limitações:
- Viés: Como o modelo aprende com dados existentes, pode acabar reproduzindo vieses presentes nesses dados, como estereótipos de gênero ou racismo. É crucial ter consciência desses vieses e trabalhar para mitigá-los.
- Fatos vs. Ficção: O CLM foca na coerência do texto, não necessariamente em sua veracidade. Isso significa que pode gerar informações factualmente incorretas, exigindo cuidado ao utilizá-lo para tarefas que demandam precisão factual.
Avanços e Modelos:
- Mecanismos de Atenção: CLM moderno se beneficia de mecanismos de atenção, que permitem ao modelo focar em partes específicas do contexto anterior que são mais relevantes para a previsão da próxima palavra.
- Transformers: Arquiteturas como os Transformers revolucionaram o CLM, permitindo o processamento paralelo de informações e melhorando a capacidade do modelo de capturar relações de longo alcance dentro do texto.

O diagrama acima ilustra o funcionamento interno de um modelo de linguagem causal (CLM), onde o texto de entrada é processado palavra por palavra (tokenização), transformado em representações numéricas (embeddings) e analisado por um modelo com atenção mascarada para prever a próxima palavra da sequência. A cabeça de modelagem de linguagem gera previsões que são comparadas com as palavras reais, e a perda resultante é usada para ajustar os parâmetros do modelo via retropropagação, permitindo que ele aprenda com os erros e melhore sua precisão ao longo do tempo. Durante a geração de texto, as etapas de cálculo da perda e retropropagação são removidas, pois o objetivo é apenas criar novas sequências de texto coerentes e contextualmente relevantes. Fonte: TheAiEdge.io
Classificação de Sentenças: Decifrando o Código do Sentimento
Imagine um detector de emoções que analisa uma frase e identifica se ela expressa alegria, tristeza, raiva ou qualquer outra emoção. Essa é a essência da Classificação de Sentenças, permitindo aos computadores interpretar o sentimento, a intenção e outras características de um texto. Essa técnica é fundamental para tarefas como análise de sentimentos, detecção de spam e categorização de tópicos (Liu, 2012).
Como o Detector Funciona?
- Preparação: Transformando Palavras em Números
As palavras são como ingredientes de uma receita: cada uma tem um sabor e uma função específicos. Na Classificação de Sentenças, transformamos as palavras em vetores numéricos, que são como códigos que representam seu significado e função no contexto da sentença. Esses vetores, também conhecidos como embeddings de palavras, capturam as relações semânticas entre as palavras e são essenciais para o sucesso da classificação de sentenças (Mikolov et al., 2013).
- Modelagem: Escolhendo a Receita Certa
Existem diferentes “receitas” para classificar sentenças, cada uma com suas vantagens e desvantagens. Redes Neurais são modelos populares que aprendem a reconhecer padrões nos vetores das palavras e a associá-los a diferentes classes (por exemplo, positivo, negativo, neutro). A escolha do modelo depende da tarefa específica e dos recursos computacionais disponíveis (Collobert et al., 2011).
- Treinamento e Avaliação: Aperfeiçoando a Receita
O modelo é treinado com exemplos de sentenças já classificadas, como reviews de produtos ou posts de redes sociais. A cada sentença classificada, ele ajusta seus parâmetros para melhorar sua precisão. Após o treinamento, o modelo é avaliado com novas sentenças para verificar seu desempenho. O uso de conjuntos de dados de treinamento e teste separados é crucial para garantir a generalização do modelo para dados não vistos (Manning et al., 2008).
Vantagens:
- Automação: Permite analisar grandes volumes de texto de forma rápida e eficiente.
- Precisão: Modelos avançados como BERT, que utilizam a arquitetura Transformer e são pré-treinados em grandes conjuntos de dados, conseguem capturar nuances da linguagem e melhorar a precisão da classificação.
Métricas de Avaliação:
- Acurácia: Mede a porcentagem de sentenças classificadas corretamente.
- Precisão e Recall: Avaliam a capacidade do modelo de identificar corretamente as classes de interesse, considerando falsos positivos e falsos negativos.
- F1 Score: Combina precisão e recall em uma única métrica para uma avaliação mais completa do desempenho do modelo.
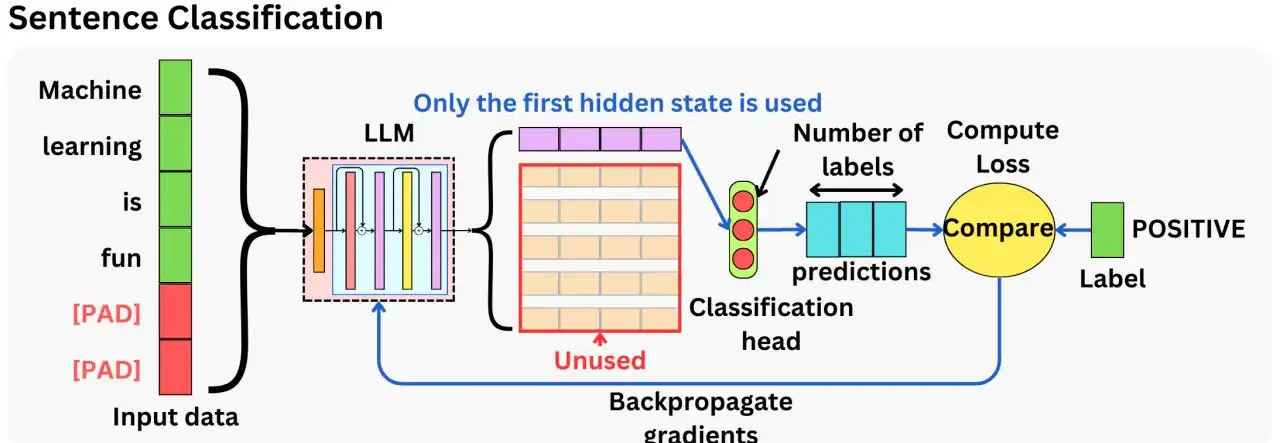
O diagrama acima ilustra o processo de classificação de sentenças, onde uma sentença é tokenizada e processada por um modelo de linguagem (LLM) para extrair seu significado geral. Ao contrário da modelagem de linguagem causal, que foca na previsão da próxima palavra, aqui apenas o primeiro estado oculto do LLM é utilizado, representando o significado completo da sentença. Este estado é passado para uma cabeça de classificação, que prevê a classe da sentença (por exemplo, positivo, negativo, neutro). As previsões são comparadas com a classe real para calcular a perda, que é usada para ajustar os parâmetros do modelo via retropropagação. As etapas de previsão de próxima palavra do LLM e os estados ocultos subsequentes não são utilizados neste processo, pois o foco está na classificação da sentença como um todo. Fonte: TheAiEdge.io
Classificação de Tokens: Rotulando os Atores do Palco
Se a Classificação de Sentenças analisa o cenário completo, a Classificação de Tokens foca nos atores individuais. Imagine um diretor de elenco que atribui papéis a cada ator em uma peça de teatro. Da mesma forma, essa técnica classifica cada palavra em um texto de acordo com sua função gramatical (substantivo, verbo, adjetivo, etc.) ou entidade (pessoa, lugar, organização, etc.). Essa tarefa, também conhecida como etiquetagem de parte da fala (POS tagging) e reconhecimento de entidade nomeada (NER), é fundamental para a compreensão profunda do significado do texto (Bird et al., 2009).
Como Funciona?
- Tokenização: Separamos o texto em palavras individuais.
- Embedding: Transformamos cada palavra em um vetor numérico que representa seu significado.
- Modelagem: Modelos baseados em Transformers são usados para analisar e classificar cada palavra.
Vantagens:
- Análise Detalhada: Permite uma compreensão mais profunda do texto, identificando elementos-chave como entidades e suas relações, o que é útil para construir representações mais ricas do significado do texto.
- Aplicações Diversas: Útil para tarefas como extração de informações, tradução automática, resposta a perguntas e construção de assistentes virtuais mais sofisticados.
Ferramentas:
- Hugging Face Transformers: Biblioteca popular que oferece modelos pré-treinados para classificação de tokens, incluindo modelos com arquitetura Transformer, que podem ser ajustados para tarefas específicas com dados adicionais.

O diagrama acima ilustra o processo de classificação de tokens, onde cada palavra de uma sentença de entrada é classificada de acordo com sua categoria gramatical ou entidade. A sentença é tokenizada e processada por um modelo de linguagem (LLM), e as representações resultantes são passadas para uma cabeça de classificação de tokens. Essa cabeça prevê a categoria de cada token (por exemplo, substantivo, verbo, adjetivo), que são então comparadas com as categorias reais (labels) para calcular a perda. A perda é usada para ajustar os parâmetros do modelo via retropropagação, permitindo que ele aprenda a classificar os tokens com maior precisão. As categorias ignoradas no diagrama representam tokens que não são relevantes para a tarefa específica, como pontuação ou palavras de parada. Fonte: TheAiEdge.io
Considerações Finais
CLM e Classificação de Sentenças/Tokens são técnicas poderosas que estão transformando a maneira como interagimos com as máquinas. Ao entender seus mecanismos e aplicações, podemos aproveitar ao máximo o potencial do PNL para criar soluções inovadoras em diversas áreas, desde a geração de textos criativos até a análise de dados complexos.
Referências Bibliográficas
- Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137–1155.
- Bird, S., Klein, E., & Loper, E. (2009). Natural language processing with Python: analyzing text with the natural language toolkit. O’Reilly Media, Inc.
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(ARTICLE), 2493–2537.
- Jurafsky, D., & Martin, J. H. (2023). Speech and language processing. Stanford University.
- Liu, B. (2012). Sentiment analysis and opinion mining. Synthesis lectures on human language technologies, 5(1), 1–167.
- Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval. Cambridge university press.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111–3119).
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008).

